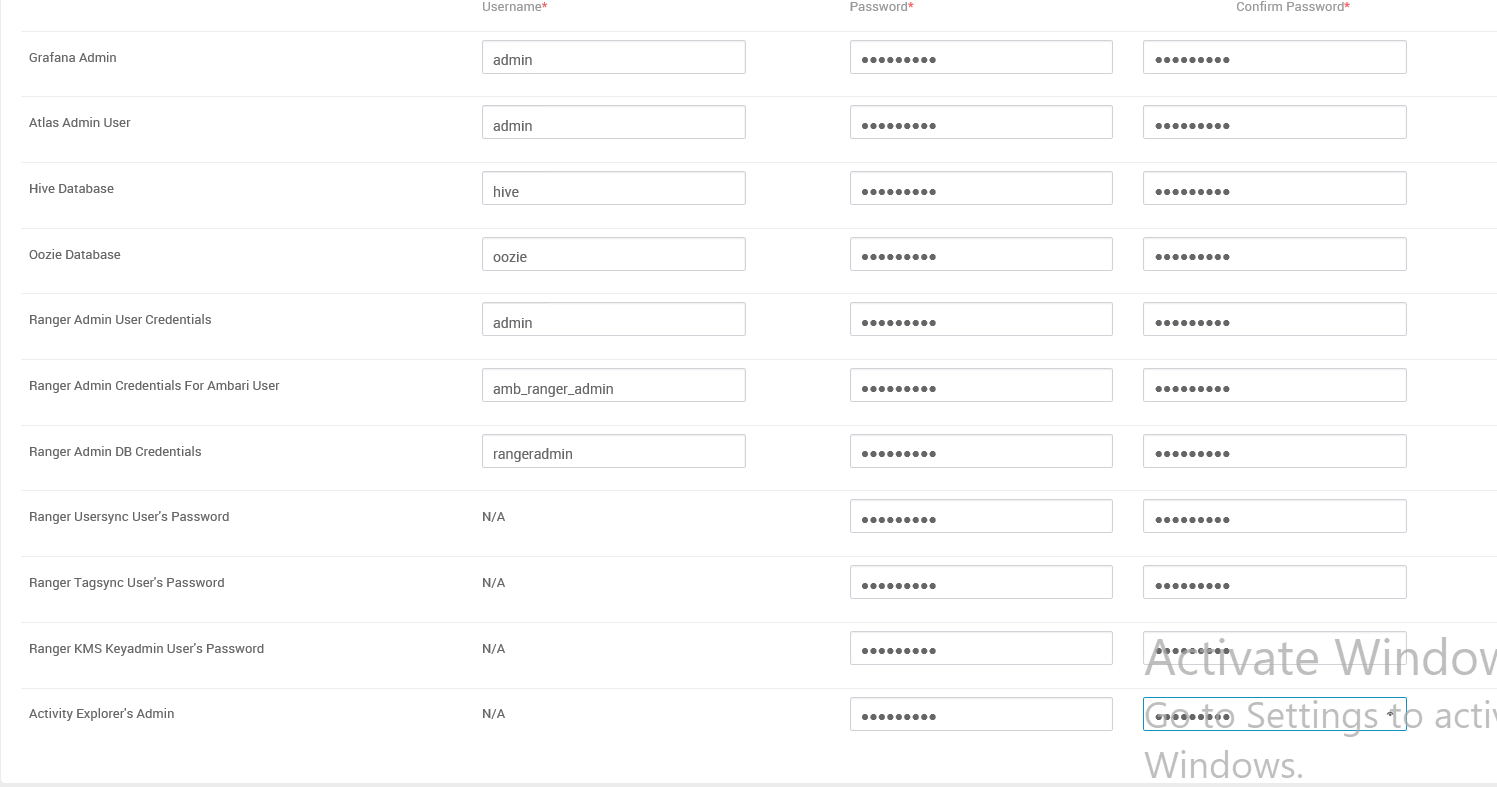
选 n。即默认设置了 Ambari GUI 的登录用户为 admin/admin。并且指定 Ambari Server 的运行用户为 root。
If you want to create a different user to run the Ambari Server, or to assign a previously created user, select y at the Customize user account for ambari-server daemon prompt, then provide a user name.
[root@master yum.repos.d]# ambari-server setup Using python /usr/bin/python Setup ambari-server Checking SELinux... SELinux status is 'disabled' Customize user account for ambari-server daemon [y/n] (n)? n Adjusting ambari-server permissions and ownership... Checking firewall status... Checking JDK... [1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8 [2] Custom JDK Enter choice (1): 2 WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts. WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts. Path to JAVA_HOME: /usr/java/jdk1.8.0_202 Validating JDK on Ambari Server...done. Completing setup... Configuring database... Enter advanced database configuration [y/n] (n)? n Configuring database... Default properties detected. Using built-in database. Configuring ambari database... Checking PostgreSQL... Running initdb: This may take up to a minute. Initializing database ... OK
About to start PostgreSQL Configuring local database... Configuring PostgreSQL... Restarting PostgreSQL Creating schema and user... done. Creating tables... done. Extracting system views... ambari-admin-2.7.4.0-118.jar ........... Adjusting ambari-server permissions and ownership... Ambari Server 'setup' completed successfully.
# 解压 $ mv mysql-5.7.32-linux-glibc2.12-x86_64.tar.gz /usr/local $ cd /usr/local $ tar -xzvf mysql-5.7.32-linux-glibc2.12-x86_64.tar.gz # Establish soft links for future upgrades $ ln -s mysql-5.7.27-linux-glibc2.12-x86_64 mysql # Modify users and user groups of all files under mysql folder $ chown -R mysql:mysql mysql/
# 创建配置文件 $ cd /etc $ vi my.cnf
# 安装 mysql $ cd /usr/local/mysql/bin $ ./mysqld --initialize --user=hive
# 设置开机启动,并启动 mysql $ cd /usr/local/mysql # Copy the startup script to the resource directory and modify mysql.server. It's better to modify mysqld as well. These two files are best synchronized. $ cp ./support-files/mysql.server /etc/rc.d/init.d/mysqld # Increase the execution privileges of mysqld service control scripts $ chmod +x /etc/rc.d/init.d/mysqld # Add mysqld service to system service $ chkconfig --add mysqld # Check whether the mysqld service is in effect $ chkconfig --list mysqld # mysql start $ service mysqld start # View mysql status $ service mysqld status # Check mysql related processes $ ps aux|grep mysql
# 配置环境变量 $ vi /etc/profile export PATH=$PATH:/usr/local/mysql/bin $ source /etc/profile
# 更新 root 密码 $ mysql -uroot -p $ mysql> set password for root@localhost=password("root"); # 配置 remote access to the mysql $ mysql> use mysql $ mysql> update user set host='%'where user='root'; $ mysql> select host,user from user; $ mysql> grant all privileges on *.* to 'root'@'%' identified by 'yourPassword'; $ mysql> flush privileges;
CREATE DATABASE ambari; use ambari; CREATE USER 'ambari'@'%' IDENTIFIED BY 'ambari'; GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'%'; CREATE USER 'ambari'@'localhost' IDENTIFIED BY 'ambar'; GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'localhost'; CREATE USER 'ambari'@'master' IDENTIFIED BY 'ambari'; GRANT ALL PRIVILEGES ON *.* TO 'ambari'@'master'; FLUSH PRIVILEGES; source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
CREATE DATABASE hive; use hive; CREATE USER 'hive'@'%' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%'; CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost'; CREATE USER 'hive'@'master' IDENTIFIED BY 'hive'; GRANT ALL PRIVILEGES ON *.* TO 'hive'@'master'; FLUSH PRIVILEGES; CREATE DATABASE oozie; use oozie; CREATE USER 'oozie'@'%' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'%'; CREATE USER 'oozie'@'localhost' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'localhost'; CREATE USER 'oozie'@'master' IDENTIFIED BY 'oozie'; GRANT ALL PRIVILEGES ON *.* TO 'oozie'@'master'; FLUSH PRIVILEGES;
[client] # Client settings, the default connection parameters for the client port = 3306 # Default connection port socket = /home/mysql/hive/3306/tmp/mysql.sock # For socket sockets for local connections, the mysqld daemon generates this file
[mysqld] # Server Basic Settings # Foundation setup user = hive bind-address = 0.0.0.0 # Allow any ip host to access this database server-id = 1 # The unique number of Mysql service Each MySQL service Id needs to be unique port = 3306 # MySQL listening port basedir = /usr/local/mysql # MySQL installation root directory datadir = /home/mysql/hive/3306/data # MySQL Data File Location tmpdir = /home/mysql/hive/3306/tmp # Temporary directories, such as load data infile, will be used socket = /home/mysql/hive/3306/tmp/mysql.sock # Specify a socket file for local communication between MySQL client program and server pid-file = /home/mysql/hive/3306/log/mysql.pid # The directory where the pid file is located skip_name_resolve = 1 # Only use IP address to check the client's login, not the host name. character-set-server = utf8mb4 # Database default character set, mainstream character set support some special emoticons (special emoticons occupy 4 bytes) transaction_isolation = READ-COMMITTED # Transaction isolation level, which is repeatable by default. MySQL is repeatable by default. collation-server = utf8mb4_general_ci # The character set of database corresponds to some sort rules, etc. Be careful to correspond to character-set-server. init_connect='SET NAMES utf8mb4' # Set up the character set when client connects mysql to prevent scrambling lower_case_table_names = 1 # Is it case sensitive to sql statements, 1 means insensitive max_connections = 400 # maximum connection max_connect_errors = 1000 # Maximum number of false connections explicit_defaults_for_timestamp = true # TIMESTAMP allows NULL values if no declaration NOT NULL is displayed max_allowed_packet = 128M # The size of the SQL packet sent, if there is a BLOB object suggested to be modified to 1G interactive_timeout = 1800 # MySQL connection will be forcibly closed after it has been idle for more than a certain period of time (in seconds) wait_timeout = 1800 # The default value of MySQL wait_timeout is 8 hours. The interactive_timeout parameter needs to be configured concurrently to take effect. tmp_table_size = 16M # The maximum value of interior memory temporary table is set to 128M; for example, group by, order by with large amount of data may be used as temporary table; if this value is exceeded, it will be written to disk, and the IO pressure of the system will increase. max_heap_table_size = 128M # Defines the size of memory tables that users can create query_cache_size = 0 # Disable mysql's cached query result set function; later test to determine whether to turn on or not based on business conditions; in most cases, close the following two items query_cache_type = 0 # Memory settings allocated by user processes, and each session will allocate memory size for parameter settings read_buffer_size = 2M # MySQL read buffer size. Requests for sequential table scans allocate a read buffer for which MySQL allocates a memory buffer. read_rnd_buffer_size = 8M # Random Read Buffer Size of MySQL sort_buffer_size = 8M # Buffer size used for MySQL execution sort binlog_cache_size = 1M # A transaction produces a log that is recorded in Cache when it is not committed, and persists the log to disk when it needs to be committed. Default binlog_cache_size 32K
back_log = 130 # How many requests can be stored on the stack in a short time before MySQL temporarily stops responding to new requests; the official recommendation is back_log = 50 + (max_connections/5), with a cap of 900 # log setting log_error = /home/mysql/hive/3306/log/error.log # Database Error Log File slow_query_log = 1 # Slow Query sql Log Settings long_query_time = 1 # Slow query time; Slow query over 1 second slow_query_log_file = /home/mysql/hive/3306/log/slow.log # Slow Query Log Files log_queries_not_using_indexes = 1 # Check sql that is not used in the index log_throttle_queries_not_using_indexes = 5 # Represents the number of SQL statements per minute that are allowed to be logged to a slow log and are not indexed. The default value is 0, indicating that there is no limit. min_examined_row_limit = 100 # The number of rows retrieved must reach this value before they can be recorded as slow queries. SQL that returns fewer than the rows specified by this parameter is not recorded in the slow query log. expire_logs_days = 5 # MySQL binlog log log file saved expiration time, automatically deleted after expiration # Master-slave replication settings log-bin = mysql-bin # Open mysql binlog function binlog_format = ROW # The way a binlog records content, recording each row being manipulated binlog_row_image = minimal # For binlog_format = ROW mode, reduce the content of the log and record only the affected columns # Innodb settings innodb_open_files = 500 # Restrict the data of tables Innodb can open. If there are too many tables in the library, add this. This value defaults to 300 innodb_buffer_pool_size = 64M # InnoDB uses a buffer pool to store indexes and raw data, usually 60% to 70% of physical storage; the larger the settings here, the less disk I/O you need to access the data in the table. innodb_log_buffer_size = 2M # This parameter determines the size of memory used to write log files in M. Buffers are larger to improve performance, but unexpected failures can result in data loss. MySQL developers recommend settings between 1 and 8M innodb_flush_method = O_DIRECT # O_DIRECT reduces the conflict between the cache of the operating system level VFS and the buffer cache of Innodb itself. innodb_write_io_threads = 4 # CPU multi-core processing capability settings are adjusted according to read-write ratio innodb_read_io_threads = 4 innodb_lock_wait_timeout = 120 # InnoDB transactions can wait for a locked timeout second before being rolled back. InnoDB automatically detects transaction deadlocks and rolls back transactions in its own lock table. InnoDB notices the lock settings with the LOCK TABLES statement. The default value is 50 seconds. innodb_log_file_size = 32M # This parameter determines the size of the data log file. Larger settings can improve performance, but also increase the time required to recover the failed database.
# 查看 hdp 各服务的日志 $ cd /usr/hdp/3.1.4.0-315/hbase/logs/hbase/hbase-hbase-regionserver-slave2.log # 或者在 var 下看也一样,不知道是放了软 link 还是什么,日志好像是一样的 $ cd /var/log/hbase/hbase-hbase-regionserver-slave2.log
error detail: This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you might want to use the less safe log_bin_trust_function_creators variable)
ERROR Java::OrgApacheHadoopHbaseIpc::RemoteWithExtrasException: org.apache.hadoop.hbase.coprocessor.CoprocessorException: HTTP 404 Error: HTTP 404 at org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor.grant(RangerAuthorizationCoprocessor.java:1261) at org.apache.ranger.authorization.hbase.RangerAuthorizationCoprocessor.grant(RangerAuthorizationCoprocessor.java:1072) at org.apache.hadoop.hbase.protobuf.generated.AccessControlProtos$AccessControlService$1.grant(AccessControlProtos.java:10023) at org.apache.hadoop.hbase.protobuf.generated.AccessControlProtos$AccessControlService.callMethod(AccessControlProtos.java:10187) at org.apache.hadoop.hbase.regionserver.HRegion.execService(HRegion.java:8135) at org.apache.hadoop.hbase.regionserver.RSRpcServices.execServiceOnRegion(RSRpcServices.java:2426) at org.apache.hadoop.hbase.regionserver.RSRpcServices.execService(RSRpcServices.java:2408) at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42010) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:131) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
File "/usr/hdp/current/atlas-server/bin/atlas_start.py", line 163, in returncode = main() File "/usr/hdp/current/atlas-server/bin/atlas_start.py", line 73, in main mc.expandWebApp(atlas_home) File "/usr/hdp/3.1.4.0-315/atlas/bin/atlas_config.py", line 160, in expandWebApp jar(atlasWarPath) File "/usr/hdp/3.1.4.0-315/atlas/bin/atlas_config.py", line 213, in jar process = runProcess(commandline) File "/usr/hdp/3.1.4.0-315/atlas/bin/atlas_config.py", line 249, in runProcess p = subprocess.Popen(commandline, stdout=stdoutFile, stderr=stderrFile, shell=shell) File "/usr/lib64/python2.7/subprocess.py", line 711, in __init__ errread, errwrite) File "/usr/lib64/python2.7/subprocess.py", line 1327, in _execute_child raise child_exception OSError: [Errno 2] No such file or directory
通过在 atlas_config.py 中添加 log,发现最后是在执行 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre/bin/jar -xf /usr/hdp/3.1.4.0-315/atlas/server/webapp/atlas.war 时报错,找不到的是 jar 命令. 原因是 jar 是 jdk 中的命令,而使用的默认 openjdk 其实只安装了 jre.
1 2 3 4 5 6 7 8
# 查看所有的 openjdk 列表 $ yum list | grep jdk
# 安装 jdk $ yum install java-1.8.0-openjdk.x86_64
# copy jar 到指定目录 $ cp /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/bin/jar /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre/bin/
ApplicationMaster: Unregistering ApplicationMaster with FAILED (diag message: User class threw exception: javax.xml.parsers.FactoryConfigurationError: Provider for class javax.xml.parsers.DocumentBuilderFactory cannot be created at javax.xml.parsers.FactoryFinder.findServiceProvider(FactoryFinder.java:311) at javax.xml.parsers.FactoryFinder.find(FactoryFinder.java:267) at javax.xml.parsers.DocumentBuilderFactory.newInstance(DocumentBuilderFactory.java:120) at org.apache.hadoop.conf.Configuration.asXmlDocument(Configuration.java:3442) at org.apache.hadoop.conf.Configuration.writeXml(Configuration.java:3417) at org.apache.hadoop.conf.Configuration.writeXml(Configuration.java:3388) at org.apache.hadoop.conf.Configuration.writeXml(Configuration.java:3384) at org.apache.hadoop.hive.conf.HiveConf.getConfVarInputStream(HiveConf.java:2410) at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:2703) at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:2657) at com.ftms.datapipeline.common.HiveMetaStoreUtil$.hiveConf(HiveMetaStoreUtil.scala:18) at com.ftms.datapipeline.common.HiveMetaStoreUtil$.createHiveMetaStoreClient(HiveMetaStoreUtil.scala:23) at com.ftms.datapipeline.common.HiveMetaStoreUtil$.getHiveMetaStoreClient(HiveMetaStoreUtil.scala:34) at com.ftms.datapipeline.common.HiveMetaStoreUtil$.getHiveTablePartitionCols(HiveMetaStoreUtil.scala:78) at com.ftms.datapipeline.common.HiveMetaStoreUtil$.getHiveTablePartitionColNames(HiveMetaStoreUtil.scala:73) at com.ftms.datapipeline.common.HiveDataSource$.buildInsertSql(HiveDataSource.scala:7) at com.ftms.datapipeline.common.HiveDataSource$.save(HiveDataSource.scala:42) at com.ftms.datapipeline.tasks.dwd.DCompany$.main(DCompany.scala:197) at com.ftms.datapipeline.tasks.dwd.DCompany.main(DCompany.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$4.run(ApplicationMaster.scala:721) Caused by: java.lang.RuntimeException: Provider for class javax.xml.parsers.DocumentBuilderFactory cannot be created at javax.xml.parsers.FactoryFinder.findServiceProvider(FactoryFinder.java:308) ... 23 more Caused by: java.util.ServiceConfigurationError: javax.xml.parsers.DocumentBuilderFactory: Provider org.apache.xerces.jaxp.DocumentBuilderFactoryImpl not found at java.util.ServiceLoader.fail(ServiceLoader.java:239) at java.util.ServiceLoader.access$300(ServiceLoader.java:185) at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:372) at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:404) at java.util.ServiceLoader$1.next(ServiceLoader.java:480) at javax.xml.parsers.FactoryFinder$1.run(FactoryFinder.java:294) at java.security.AccessController.doPrivileged(Native Method) at javax.xml.parsers.FactoryFinder.findServiceProvider(FactoryFinder.java:289) ... 23 more
Spark
在 yarn-client 模式下运行 spark
会出现 Library directory '...\assembly\target\scala-2.11\jars' does not exist; make sure Spark is built.,这个大致原因是 yarn-client 模式下
Running Spark on YARN requires a binary distribution of Spark which is built with YARN support. Binary distributions can be downloaded from the downloads page of the project website. To build Spark yourself, refer to Building Spark. To make Spark runtime jars accessible from YARN side, you can specify spark.yarn.archive or spark.yarn.jars. For details please refer to Spark Properties. If neither spark.yarn.archive nor spark.yarn.jars is specified, Spark will create a zip file with all jars under $SPARK_HOME/jars and upload it to the distributed cache
# 启动服务 $ service clickhouse-server start Start clickhouse-server service: Path to data directory in /etc/clickhouse-server/config.xml: /var/lib/clickhouse/
# 通过 client 验证运行成功 $ clickhouse-client ClickHouse client version 19.4.3.11. Connecting to localhost:9000 as user default. Connected to ClickHouse server version 19.4.3 revision 54416.
master :) select 1
SELECT 1
┌─1─┐ │ 1 │ └───┘
1 rows inset. Elapsed: 0.001 sec.
client 启动失败
error detail:
1 2 3
ClickHouse client version 20.8.3.18. Connecting to localhost:9000 as user default. Code: 102. DB::NetException: Unexpected packet from server localhost:9000 (expected Hello or Exception, got Unknown packet)