sqoop
Concept
Sqoop: sq are the first two of “sql”, oop are the last three of “hadoop”. It transfers bulk data between hdfs and relational database servers. It supports:
- Full Load
- Incremental Load
- Parallel Import/Export (throught mapper jobs)
- Compression
- Kerberos Security Integration
- Data loading directly to HIVE
Sqoop cannot import .csv files into hdfs/hive. It only support databases / mainframe datasets import.
Architecture
Sqoop provides CLI, thus you can use a simple command to conduct import/export.
The import/export are executes in fact through map tasks.
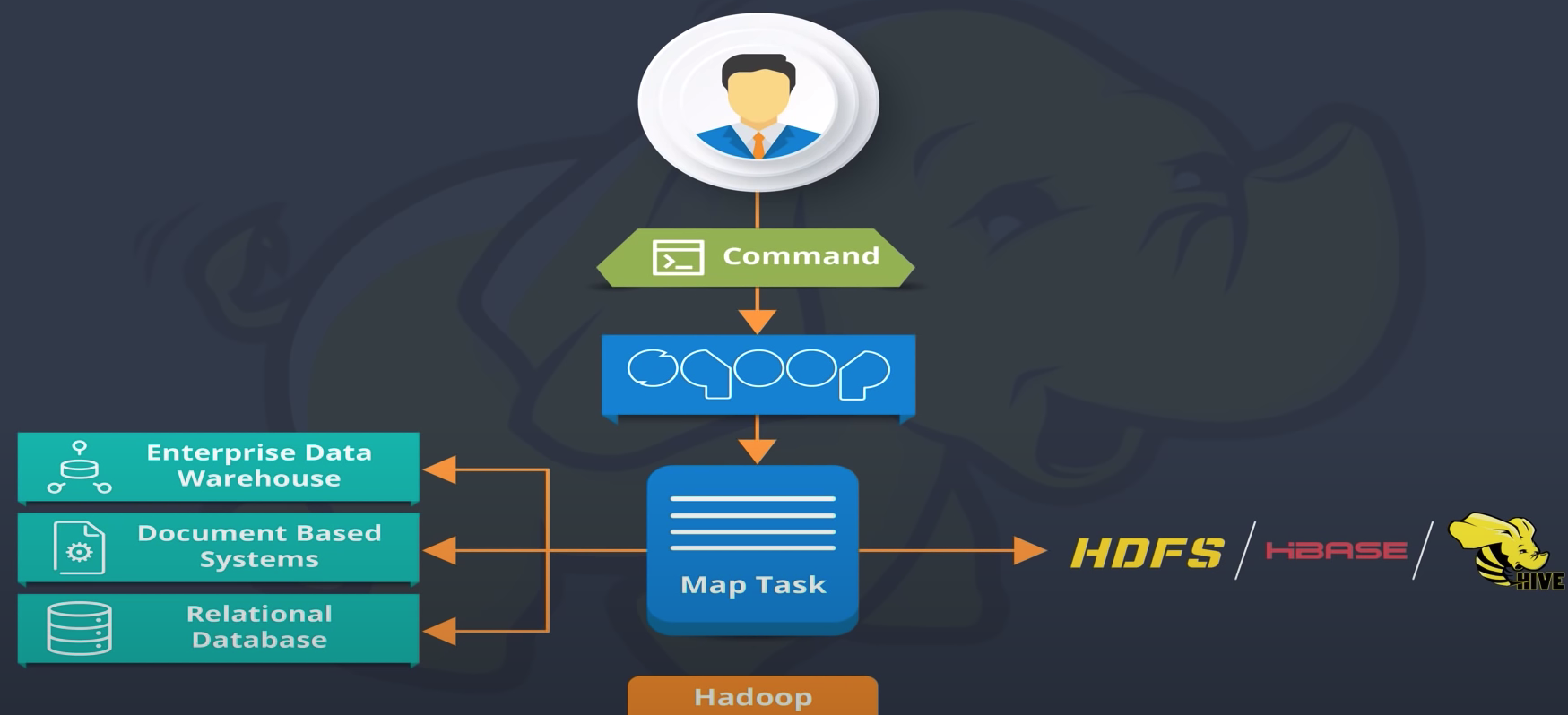
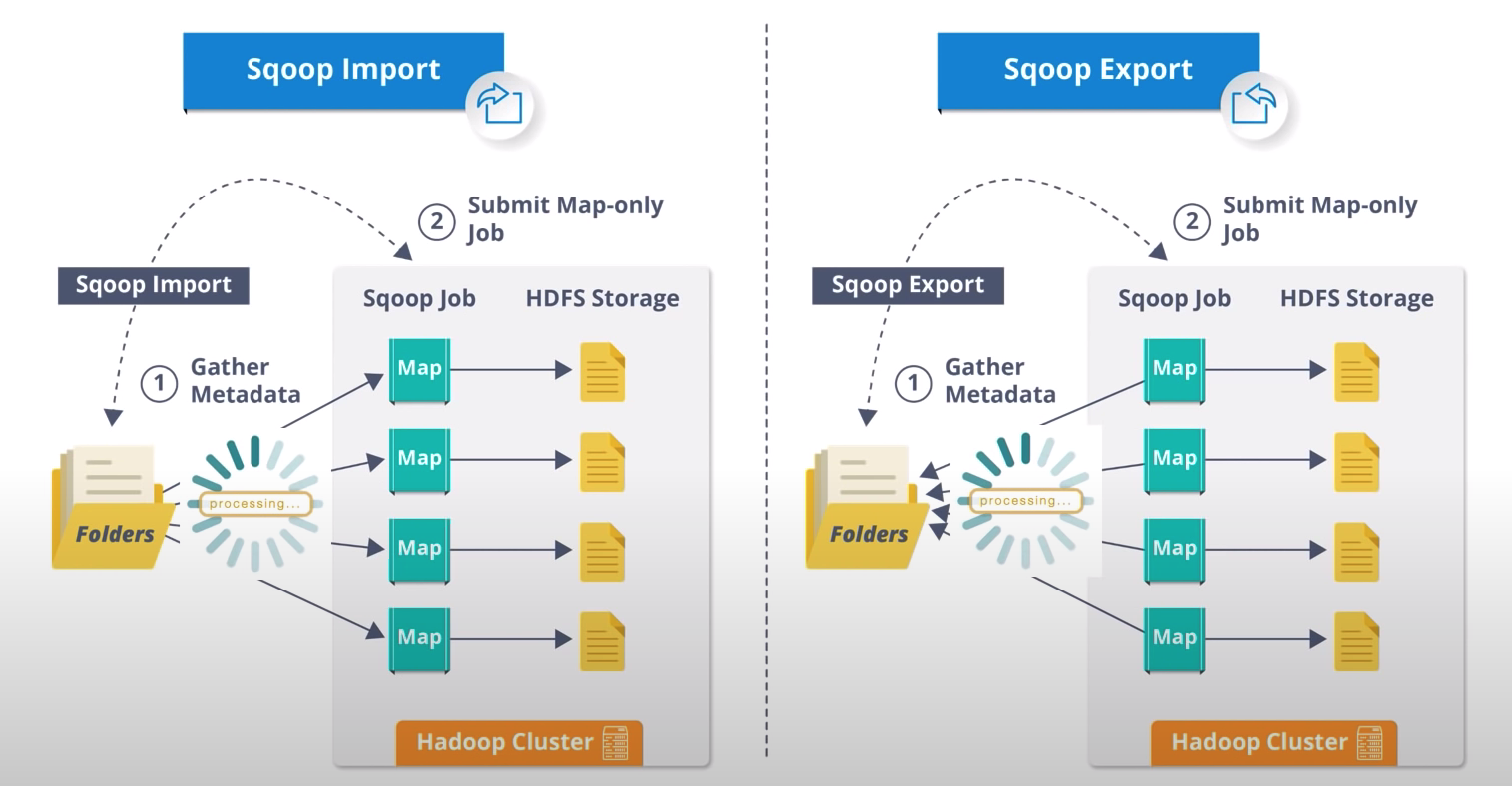
When Import from DB:
- it split to some map tasks. And each map task will connect to DB, and fetch some rows/tables, and write it to a file into HDFS
When export to DB:
- it also split to some map tasks. And each map task will fetch a HDFS file, and write each record in the file as a row by specified delimiter to some table.
Sqoop v.s. Spark jdbc
sqoop uses mapreduce technique, while spark is a revolutionary engine to replace mapreduce technique with its in-memory execution and DAG smartness. Thus Spark jdbc is way faster than sqoop.
- You can combine all the read, transform and write operations into one script/program instead of reading it separately through SQOOP in one script and then doing transformation and write in another.
- You can define a new split column on the fly (using functions like ORA_HASH) if you want the data to be partitioned in a proper way.
- You can control the number of connection to the database. Increasing the number of connection will surely speed up your data import.
Common Commands
1 | $ sqoop import \ |
Incremental Import
增量导入时,sqoop 需要识别到增量数据,有三种方法:
- 根据自增字段识别新数据(append 模式):可以直接识别新数据并导入到 hive 中
- 根据修改时间识别新数据(lastmodified 模式):要求这个字段会随数据的改变而改变,但是似乎只能导入到 hdfs 中,不能直接导入到 hive 中。导入时,可以通过制定
--merge-key id来按 id 字段进行合并,或者之后通过sqoop merge功能单独运行 - 根据 where 或 query 识别新数据:可能之后只能通过
sqoop merge来 merge 数据
目前 sqoop 导入时不能识别删除数据,都需要通过其他方式来解决(对比数据,或者数据上有 delete 标识符时,通过 Incrementally Updating a Table 来实现)
append 模式
1 | sqoop import \ |
lastmodified 模式
1 | sqoop import \ |
条件查询
这里写的都是全量导入 hive。如果要增量,只能先导入到 hdfs,然后再做 merge
–where
1 | sqoop import \ |
–query
1 | sqoop import \ |
运行 sqoop action
在数据接入时,特别是连接数据库增量导入数据时,这种周期性任务的执行,有很多种方式:
- 写一个 long running 脚本,不断执行增量 import
- 采用 Oozie 等调度工具来运行