data lake
Concept
数据湖是:
- 装有一些便于提取、分析、搜索、挖掘的设备(本身不具备分析能力,是其他分析工具可以方便的在湖上运行,而不需要把湖的数据挪出去再分析)
- 存放各种数据(格式不统一,原始数据):结构、半结构、非结构化
- 来源各种各样,能很方便的导入到数据湖
数据湖就是原始数据保存区. 虽然这个概念国内谈的少,但绝大部分互联网公司都已经有了。国内一般把整个HDFS叫做数据仓库(广义),即存放所有数据的地方,而国外一般叫数据湖(data lake)。把需要的数据导入到数据湖,如果你想结合来自数据湖的信息和客户关系管理系统(CRM)里面的信息,我们就进行连接,只有需要时才执行这番数据结合。
数据湖是多结构数据的系统或存储库,它们以原始格式和模式存储,通常作为对象“blob”或文件存储。数据湖的主要思想是对企业中的所有数据进行统一存储,从原始数据(源系统数据的精确副本)转换为用于报告、可视化、分析和机器学习等各种任务的目标数据。数据湖中的数据包括结构化数据(关系数据库数据),半结构化数据(CSV、XML、JSON等),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视频),从而形成一个容纳所有形式数据的集中式数据存储。
数据湖从本质上来讲,是一种企业数据架构方法,物理实现上则是一个数据存储平台,用来集中化存储企业内海量的、多来源,多种类的数据,并支持对数据进行快速加工和分析 (支持直接在数据湖上运行分析,而无需将数据移至单独的分析系统)。从实现方式来看,目前Hadoop是最常用的部署数据湖的技术,但并不意味着数据湖就是指Hadoop集群。为了应对不同业务需求的特点,MPP数据库+Hadoop集群+传统数据仓库这种“混搭”架构的数据湖也越来越多出现在企业信息化建设规划中。
Data Lake: 数据湖Data Swamp: 数据沼泽Data Mart: 数据集市Data Warehouse: 数据仓库Data Cube:数据立方体Data Stream:数据流Data Virtualization:数据虚拟化
错误认知
- 错误认知1: 数据湖仅用于“存储”数据
- 支持对数据进行快速加工和分析。支持直接在数据湖上运行分析,而无需将数据移至单独的分析系统
- 错误认知2:数据湖仅存储“原始”数据
- 需要有定义的机制来编目和保护数据。这些元素并非原始数据,而是对数据湖的管理数据。
数据和和分析解决方案的基本要素
组织构建数据湖和分析平台时,他们需要考虑许多关键功能,包括:
数据移动(支持大规模的数据以原始形式导入)
数据湖允许您导入任何数量的实时获得的数据。您可以从多个来源收集数据,并以其原始形式将其移入到数据湖中。此过程允许您扩展到任何规模的数据,同时节省定义数据结构、Schema 和转换的时间。
安全地存储和编目数据(编目使得数据是被监督的,可用的)
数据湖允许您存储关系数据(例如,来自业务线应用程序的运营数据库和数据)和非关系数据(例如,来自移动应用程序、IoT 设备和社交媒体的运营数据库和数据)。它们还使您能够通过对数据进行爬网、编目和建立索引来了解湖中的数据。最后,必须保护数据以确保您的数据资产受到保护。
是数据湖里的数据本身有索引吗?还是基于数据湖做catalog、元数据管理等?catalog 即是对数据湖数据的索引???
分析(可以直接在数据湖上,运行快速加工和分析)
数据湖允许组织中的各种角色(如数据科学家、数据开发人员和业务分析师)通过各自选择的分析工具和框架来访问数据。这包括 Apache Hadoop、Presto 和 Apache Spark 等开源框架,以及数据仓库和商业智能供应商提供的商业产品。数据湖允许您运行分析,而无需将数据移至单独的分析系统。
机器学习(在数据湖上进行机器学习)
数据湖将允许组织生成不同类型的见解,包括报告历史数据以及进行机器学习(构建模型以预测可能的结果),并建议一系列规定的行动以实现最佳结果。
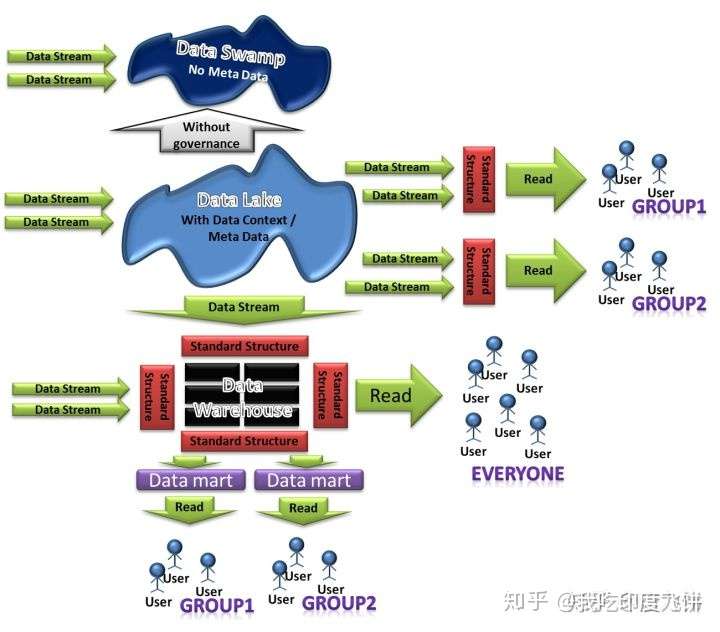
Data swamp
搭建数据湖容易,但是让数据湖发挥价值是很难。如果只是一直往里面灌数据,而应用场景极少,没有输出或者极少输出,形成单向湖。
企业的业务是实时在变化的,这代表着沉积在数据湖中的数据定义、数据格式实时都在发生的转变,企业的大型数据湖对企业数据治理(Data Governance)提升了更高的要求。大部分使用数据湖的企业在数据真的需要使用的时候,往往因为数据湖中的数据质量太差而无法最终使用。数据湖,被企业当成一个大数据的垃圾桶,最终数据湖成为臭气熏天,存储在Hadoop当中的数据成为无人可以清理的数据沼泽.
数据湖架构的主要挑战是存储原始数据而不监督内容。对于使数据可用的数据湖,它需要有定义的机制来编目和保护数据。没有这些元素,就无法找到或信任数据,从而导致出现“数据沼泽”。 满足更广泛受众的需求需要数据湖具有管理、语义一致性和访问控制。
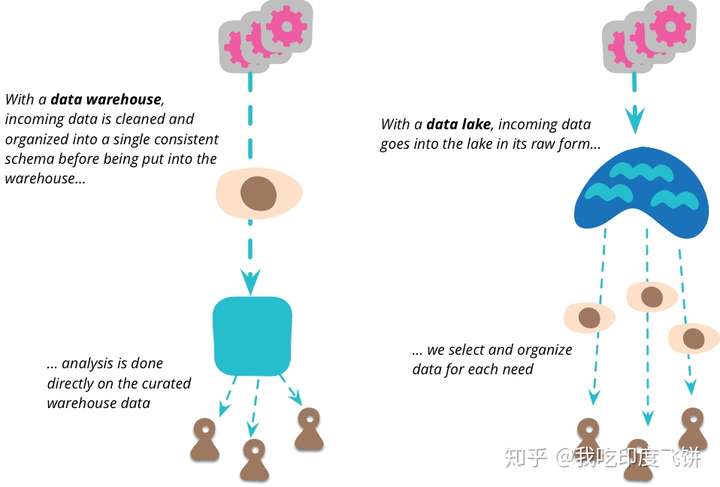
Data Lake v.s. Data Warehouse
数据仓库里的数据都满足特定的 schema,而数据湖则没有。仓库里的数据是简单整理过的,湖里的则是原始的(但不全是原始的)。仓库里的来源也都是规范的关系数据,而湖里则什么都有。
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得见解。
随着使用数据仓库的组织看到数据湖的优势,他们正在改进其仓库以包括数据湖,并启用各种查询功能、数据科学使用案例和用于发现新信息模型的高级功能。Gartner 将此演变称为“分析型数据管理解决方案”或“DMSA”。
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| **数据质量 ** | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |