spark
Concept
spark is a fast and general-purpose cluster computing system like Hadoop Map-reduce. It runs on the clusters.
Spark Ecosystem
The components of Apache Spark Ecosystem

- spark core: cluster computing system. Provide API to write computing functions.
- Spark SQL. SQL for data processing, like hive?
- MLlib for machine learning.
- GraphX for graph processing
- Spark Streaming.
Core concepts???
- RDDs (Resilient Distributed Datasets): RDDs are the fundamental data structure in Spark. They are immutable and can be split into multiple partitions that can be processed in parallel.
- Transformations: Transformations are operations that are applied to RDDs to create new RDDs. Transformations are lazy, which means that they are not executed until an action is called.
- Actions: Actions are operations that are applied to RDDs to produce a result. Actions trigger the execution of all of the transformations that have been applied to the RDD.
- DAG (Directed Acyclic Graph): A DAG is a graph that represents the dependencies between transformations. Spark uses DAGs to schedule and execute transformations.
- SparkContext: The SparkContext is the entry point to the Spark API. It provides methods for creating RDDs, submitting jobs, and managing resources.
- SparkSession: The SparkSession is a newer API that provides a simpler and more concise way to use Spark. It is built on top of the SparkContext and provides a number of additional features, such as support for SQL and machine learning.
Spark Core is the foundation of Apache Spark and provides the essential functionality and APIs for distributed data processing. Here are some key Spark Core concepts explained with examples:
- Resilient Distributed Datasets (RDDs): RDDs are the fundamental data structure in Spark Core. They represent an immutable distributed collection of objects that can be processed in parallel across a cluster. RDDs can be created from data in Hadoop Distributed File System (HDFS), local file systems, or by transforming existing RDDs. Here’s an example of creating an RDD from a list of numbers:
1 | val numbers = List(1, 2, 3, 4, 5) |
- Transformations: Transformations are operations performed on RDDs to create new RDDs. Transformations are lazy and do not execute immediately but build a lineage graph to track the transformations applied. Examples of transformations include
map,filter,flatMap, andreduceByKey. Here’s an example of applying a transformation to square each element of an RDD:
1 | val squaredRDD = rdd.map(num => num * num) |
- Actions: Actions are operations that trigger the execution of computations and return results or write data to external systems. Actions initiate the evaluation of RDDs and can trigger lineage-based optimizations. Examples of actions include
collect,count,reduce, andsaveAsTextFile. Here’s an example of performing a sum operation on an RDD:
1 | val sum = squaredRDD.reduce((a, b) => a + b) |
- Spark Context: The Spark Context (
sparkContext) is the entry point and the central coordinator for Spark Core. It establishes a connection to the Spark cluster and manages the execution environment. The Spark Context is used to create RDDs and perform operations on them. Here’s an example of creating a Spark Context:
1 | import org.apache.spark.{SparkConf, SparkContext} |
These are the core concepts of Spark Core that lay the foundation for distributed data processing in Apache Spark. By understanding RDDs, transformations, actions, and the Spark Context, you can build powerful and scalable data processing applications using Spark.
Spark Core
Spark Core is the fundamental unit of the whole Spark project. Its key features are:
- It is in charge of essential I/O functionalities.
- Provide API to defines and manipulate the RDDs. Significant in programming and observing the role of the Spark cluster.
- Task dispatching, scheduling
- Fault recovery.
- It overcomes the snag of** MapReduce** by using in-memory computation.
Spark makes use of Special data structure known as RDD (Resilient Distributed Dataset). Spark Core is distributed execution engine with all the functionality attached on its top. For example, MLlib, SparkSQL, GraphX, Spark Streaming. Thus, allows diverse workload on single platform. All the basic functionality of Apache Spark Like in-memory computation, fault tolerance, memory management, monitoring, task scheduling is provided by Spark Core.
Apart from this Spark also provides the basic connectivity with the data sources. For example, HBase, Amazon S3, **HDFS **etc.
Action, Job, Stage, Task
Actions are RDD’s operation. reduce, collect, takeSample, take, first, saveAsTextfile, saveAsSequenceFile, countByKey, foreach are common actions in Apache spark.
In a Spark application, when you invoke an action on RDD, a job is created. Jobs are the main function that has to be done and is submitted to Spark. The jobs are divided into stages depending on how they can be separately carried out (mainly on shuffle boundaries). Then, these stages are divided into tasks. Tasks are the smallest unit of work that has to be done the executor.
When you call collect() on an RDD or Dataset, the whole data is sent to the Driver. This is why you should be careful when calling collect().
An example:
let’s say you need to do the following:
- Load a file with people names and addresses into RDD1
- Load a file with people names and phones into RDD2
- Join RDD1 and RDD2 by name, to get RDD3
- Map on RDD3 to get a nice HTML presentation card for each person as RDD4
- Save RDD4 to file.
- Map RDD1 to extract zipcodes from the addresses to get RDD5
- Aggregate on RDD5 to get a count of how many people live on each zipcode as RDD6
- Collect RDD6 and prints these stats to the stdout.
So,
- The *driver program* is this entire piece of code, running all 8 steps.
- Producing the entire HTML card set on step 5 is a *job* (clear because we are using the save action, not a transformation). Same with the collect on step 8
- Other steps will be organized into *stages*, with each job being the result of a sequence of stages. For simple things a job can have a single stage, but the need to repartition data (for instance, the join on step 3) or anything that breaks the locality of the data usually causes more stages to appear.
- You can think of stages as computations that produce intermediate results, which can in fact be persisted. For instance, we can persist RDD1 since we’ll be using it more than once, avoiding recomputation.
- All 3 above basically talk about how the logic of a given algorithm will be broken. In contrast, a *task* is a particular piece of data that will go through a given stage, on a given executor.
RDD
RDD 数据模型
| 属性名 | 成员类型 | 属性含义 |
|---|---|---|
| dependencies | 变量 | 生成该RDD所依赖的父RDD |
| compute | 方法 | 生成该RDD的计算接口 |
| partitions | 变量 | 该RDD的所有数据分片实体 |
| partitioner | 方法 | 划分数据分片的规则 |
| preferredLocations | 变量 | 数据分片的物理位置偏好 |
SparkContext
SparkContext is the entry point of Spark functionality. The most important step of any Spark driver application is to generate SparkContext. It allows your Spark Application to access Spark Cluster with the help of Resource Manager.
If you want to create SparkContext, first SparkConf should be made. The SparkConf has a configuration parameter that our Spark driver application will pass to SparkContext. Some of these parameter defines properties of Spark driver application. While some are used by Spark to allocate resources on the cluster, like the number, memory size, and cores used by executor running on the worker nodes.
In short, it guides how to access the Spark cluster. After the creation of a SparkContext object, we can invoke functions such as textFile, sequenceFile, parallelize etc.
Once the SparkContext is created, it can be used to create RDDs, broadcast variable, and accumulator, ingress Spark service and run jobs. All these things can be carried out until SparkContext is stopped.
1 | from __future__ import print_function |

How does it run
Cluster Mode Overview - Spark 3.4.1 Documentation
Spark core contains the main api, driver engine, scheduler… to support the cluster computing. The real computing is completed on the cluster. Spark can connect to many cluster managers(spark’s own standalone cluster manager, mesos, yarn) to complete the jobs. Typically, the process is like this:
- The user submits a spark application using the
spark-submitcommand. - Spark-submit launches the driver program on the same node in (client mode) or on the cluster (cluster mode) and invokes the main method specified by the user.
- The driver program contacts the cluster manager to ask for resources to launch executor JVMs based on the configuration parameters supplied.
- The cluster manager launches executor JVMs on worker nodes.
- The driver process scans through the user application. Based on the RDD actions and transformations in the program, Spark creates an operator graph.
- When an action (such as collect) is called, the graph is submitted to a DAG scheduler. The DAG scheduler divides the operator graph into stages.
- A stage comprises tasks based on partitions of the input data. The driver sends work to executors in the form of tasks.
- The executors process the task and the result sends back to the driver through the cluster manager.


Execution Framework???
The execution framework in Apache Spark is responsible for executing the computations on RDDs and managing the distributed processing across a cluster. Spark provides a flexible execution model that optimizes the execution of transformations and actions based on the directed acyclic graph (DAG) of the computation. Let’s explore the execution framework with examples:
- DAG Scheduling: Spark’s execution framework utilizes a DAG scheduler to analyze the sequence of transformations applied on RDDs and determine an optimal execution plan. It breaks down the computation into stages, where each stage represents a set of transformations that can be executed independently. For example:
1 | val rdd = sparkContext.parallelize(List(1, 2, 3, 4, 5)) |
In this example, Spark recognizes that the map transformation can be executed in a single stage, and the reduce action requires a separate stage.
- Task Execution: Spark’s execution framework assigns tasks to the available executors in the cluster. Each task is a unit of computation that operates on a subset of the data. The tasks are sent to the executors, where they are executed in parallel. Spark dynamically partitions the data and assigns partitions to different tasks for efficient parallel processing. For example:
1 | val data = sparkContext.parallelize(1 to 1000) |
In this example, Spark distributes the data across the cluster and assigns tasks to different partitions of the RDD for parallel execution.
- Lazy Evaluation: Spark’s execution framework incorporates lazy evaluation, which means that transformations on RDDs are not executed immediately. Instead, Spark builds a lineage graph that tracks the transformations applied to the RDDs. The transformations are evaluated only when an action is triggered. This allows Spark to optimize the execution plan based on the entire computation flow. For example:
1 | val rdd = sparkContext.parallelize(List(1, 2, 3, 4, 5)) |
In this example, Spark defers the execution of transformations until the count action is called. It optimizes the execution plan by combining the map and filter operations into a single stage.
Data Shuffling: Spark’s execution framework handles data shuffling, which is the process of redistributing data across the cluster. Shuffling occurs when operations like groupBy, sortBy, or join require data to be redistributed to ensure that related data is co-located. The execution framework optimizes data shuffling by minimizing data movement and leveraging in-memory operations when possible.
Fault Tolerance: Spark’s execution framework provides fault tolerance by maintaining the lineage information of RDDs. If a partition or task fails, Spark can use the lineage graph to recompute the lost or corrupted data. This ensures the resiliency and reliability of computations.
Overall, Spark’s execution framework efficiently manages the distributed execution of transformations and actions on RDDs. It optimizes the execution plan, leverages parallel processing, and provides fault tolerance to ensure fast and reliable data processing across large-scale clusters.
The Spark execution framework consists of the following components:
- SparkContext: The SparkContext is the entry point to the Spark API. It provides methods for creating RDDs, submitting jobs, and managing resources.
- DAGScheduler: The DAGScheduler is responsible for scheduling Spark jobs. It creates a Directed Acyclic Graph (DAG) of transformations and then schedules the execution of the DAG.
- TaskScheduler: The TaskScheduler is responsible for executing Spark jobs. It assigns tasks to executors and monitors the progress of tasks.
- Executors: Executors are the worker nodes in a Spark cluster. They are responsible for executing tasks.
- Driver: The driver is the main process in a Spark cluster. It is responsible for submitting jobs, managing resources, and collecting results.
The Spark execution framework works as follows:
- A user submits a Spark job to the driver.
- The driver creates a SparkContext.
- The SparkContext creates a DAG of transformations.
- The DAGScheduler schedules the execution of the DAG.
- The TaskScheduler assigns tasks to executors.
- The executors execute the tasks.
- The driver collects the results of the tasks.
The Spark execution framework is a powerful and flexible system that can be used to run a wide variety of Spark jobs. It is designed to be efficient and scalable, and it can be used to run jobs on a variety of cluster sizes.
Here are some examples of how the Spark execution framework can be used:
- To run a simple word count job, you can use the following code:
1 | import org.apache.spark.sql.SparkSession |
API
You can write spark function (eg. map function, reduce funciton) using Java/scala/python/R API. See api docs.
Installation On Yarn
See run spark on Yarn, https://www.linode.com/docs/databases/hadoop/install-configure-run-spark-on-top-of-hadoop-yarn-cluster/
understand spark installation
Here, we have:
machine ‘A’: which is the place to install spark and run
spark-submitscriptthis can be inside or outside of yarn cluster
spark is installed here
yarn configuration files(e.g.
yarn-site.xml), hadoop configuration files (e.g.core-site.xml) must be maintained here. And in thespark-env.sh,HADOOP_CONF_DIRandYARN_CONF_DIRmust be set to point the these configuration files.
yarn cluster: where the spark applications really run.
We don’t need to pre-install spark here.
YARN will take care of distributing the necessary Spark binaries (JAR) to the nodes dynamically when you submit a Spark application.
spark.yarn.jarsConfiguration (used inspark-submit)- specifies the Spark JARs that will be distributed to the YARN cluster when you submit your application. This version should match the Spark version installed on machine ‘A’.
- If not specified, the default jars, located in
libdirectory of your Spark installation on machine ‘A’
Key properties in
yarn-site.xmlthat can be relevant for Spark on a client machine:
1 | <!-- YARN ResourceManager address --> |
Key properties in
core-site.xmlthat can be relevant for Spark on a client machine:1
2
3
4
5<!-- Hadoop NameNode address -->
<property>
<name>fs.defaultFS</name>
<value><HADOOP_NAMENODE_ADDRESS></value>
</property>
spark versions
There are 4 versions in topic:
Version 1: Spark Dependency Version (Application Code):
- This is the version of Spark that your application code depends on when you write and build your Spark application. It includes Spark libraries and APIs used in your code.
Version 2: Installed Spark Version on Machine ‘A’ (spark-submit):
- This is the version of Spark installed on the machine from which you submit your Spark application using
spark-submit. It is the Spark version that thespark-submitscript uses to package and submit your application to the cluster.
- This is the version of Spark installed on the machine from which you submit your Spark application using
Version 3: Spark Version for Driver and Executors (spark.yarn.jars):
- This is the Spark version used by the driver program and executors running on the YARN cluster. The
spark.yarn.jarsconfiguration points to the Spark JARs (libraries) that will be distributed to the YARN cluster for executing your application. - If
spark.yarn.jarsnot specified, this version is the same as the Version 2, as the jar of that installed spark is used.
- This is the Spark version used by the driver program and executors running on the YARN cluster. The
Version 4: Spark Version Installed on YARN Cluster:
- This is the version of Spark installed on the machines in the YARN cluster where your Spark application will run. This is in fact the same as Version 3. Version 3 is the configuration, and Version 4 is the final distributed binaries based on this configuration.
Generally speaking, all these versions, in fact the first 3 versions, should point to the same spark binary distribution to avoid compatibility issues. Version 1 and Version 3 must be the same. Even though when spark.yarn.jars provided, the Version 2 may not influence at all. We still recommend to keep it the same to avoid some unknown compatible issues.
install
downloads page download the spark
tar -xvf spark-xxx.tgzconfiguration
- config in
/conf/spark-env.sh
1 | # config this to specify the installed HADOOP path |
- config in
/conf/spark-default.conf. (all configuration properties)
1 | # config the spark master |
history server config
When the spark job is running, you can access the job log by localhost:4040. When the job is finished, by default, the log is not persisted which means you can’t access it. To access the logs later, need to config the following: (see spark Monitoring and Instrumentation and using history server to replace the spark web ui)
1 | # in /conf/spark-default.conf |
example execution
- Start histroy server:
sbin/start-history-server.sh - execute spark job:
1 | $ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \ |
Then you can:
Check the job/application info in yarn:
http://localhost:8088/cluster/appsCheck the job/application using Spark history server:
http://localhost:18080/
Glossary
NoteThe following table summarizes terms you’ll see used to refer to cluster concepts:
| Term | Meaning |
|---|---|
| Application | User program built on Spark. Consists of a driver program and executors on the cluster. |
| Application jar | A jar containing the user’s Spark application. In some cases users will want to create an “uber jar” containing their application along with its dependencies**. The user’s jar should never include Hadoop or Spark libraries, however, these will be added at runtime.** |
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Cluster manager | An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
| Deploy mode | Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
| Worker node | Any node that can run application code in the cluster |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Task | A unit of work that will be sent to one executor |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
Deploy mode
yarn-client vs yarn-cluster
yarn-client vs yarn-cluster 深度剖析
Spark K8s Deployment & Execution Core Knowledge Cheat Sheet
| Module | Core Knowledge Points | Key Details |
|---|---|---|
| K8s Deployment Paradigm | No Predefined Spark Cluster | Based on Docker images; on-demand create Driver+Executor Pods; cluster is destroyed after the task completes |
| Image Layered Strategy | Base image: Contains OS, Java, and Spark core Business image: Builds on the base image, only adds project dependencies (e.g., requirements.txt, JAR packages) |
|
| Advantages | Consistency across development/test/production environments; Spark version upgrades only require replacing the base image | |
spark-submit Role |
Universal Submission Script | Specify the resource manager via --master:--master yarn → YARN cluster--master k8s://<API address> → K8s cluster--master local[*] → Run locally |
| K8s Submission Flow | 1. Connect to K8s API and create a Driver Pod 2. After the Driver Pod starts, request to create Executor Pods 3. Form a temporary cluster to execute the task |
|
| Relationship with Docker Instructions | Overrides CMD/ENTRYPOINT in the Dockerfile; tail -f /dev/null in the image is only a placeholder for manual container startup |
|
| Multi-Language SDK Execution Logic | Unified Execution Flow | Any language code → Generate Logical Execution Plan → Catalyst Optimizer generates Physical Execution Plan → Execute on JVM |
| Language Performance Comparison | Scala/Java: Runs natively on JVM, optimal performance Python (PySpark): Rich ecosystem, but has performance overhead for UDFs |
|
| PySpark UDF Optimization | Regular UDFs: Serialize data between JVM and Python processes (high overhead) Pandas UDFs: Use Apache Arrow columnar transfer to reduce overhead |
|
| Key Execution Clarifications | Plan Generation Location | PySpark calls the JVM via Py4J to build the execution plan; logical/physical plans are stored on the JVM side |
| Efficient Execution Condition | When only using Spark built-in functions (e.g., select/filter), execution runs entirely within the JVM (benefits from Catalyst optimization) |
|
| Cross-Language Reuse | Write performance-critical logic in Scala/Java (packaged as JARs), then include them in PySpark tasks via the --jars parameter |
The Kubernetes Approach: A Modern Paradigm for Spark**
The use of a Dockerfile points to a modern, container-based deployment strategy for Spark, which is fundamentally different from the traditional YARN model.
- No Predefined Spark Cluster: Instead of a persistent, long-running Spark cluster (like on YARN), you have a general-purpose Kubernetes (K8s) cluster.
- On-Demand Spark Clusters: A temporary, job-specific Spark cluster (a Driver and its Executors) is created dynamically on Kubernetes when you submit a job*. It is destroyed once the job completes, releasing all resources.
- The Role of the Docker Image:
- The Dockerfile creates a self-contained, portable environment for your Spark application. This image packages the OS, a specific Spark version, all Python dependencies, and necessary JARs.
- This guarantees absolute consistency between development, testing, and production, eliminating “it works on my machine” issues.
- The Base Image Strategy:
- To avoid managing the full Spark installation in every project, a layered approach is used.
- A central team creates a base image (e.g.,
spark_3_5:1.6.0) that contains the OS, Java, and the core Spark distribution. - Your application’s Dockerfile starts
FROMthis base image and only adds the components specific to your app (likerequirements.txt). - Upgrading Spark becomes as simple as changing the
FROMline to a new base image version.
spark-shell vs spark-submit
Spark shell is only intended to be use for testing and perhaps development of small applications - is only an interactive shell and should not be use to run production spark applications. For production application deployment you should use spark-submit. The last one will also allow you to run applications in yarn-cluster mode
The Role and Function of spark-submit**
spark-submit is the universal launch script for all Spark applications, acting as the bridge between your code and the cluster manager.
- A Universal Client: It’s a script included in every Spark distribution that acts as a client for the chosen resource manager. The
--masterflag dictates its behavior:--master yarn: Talks to a YARN cluster.--master pyspark: Talks to the Kubernetes API server.--master local[*]: Runs locally on your machine.
- The Kubernetes Submission Process:
- You run
spark-submitwith--master pysparkand specify your application’s Docker image (--conf spark.kubernetes.container.image=...). spark-submitconnects to the K8s API and requests the creation of a Driver Pod using your image.- Once the Driver Pod is running, the Spark Driver process inside it connects back to the K8s API and requests Executor Pods.
- These pods form a temporary Spark cluster to run the job.
- You run
spark-submitvs. DockerENTRYPOINT:- The
spark-submitcommand overrides theCMDorENTRYPOINTin your Dockerfile. - The Dockerfile’s
CMD "tail -f /dev/null"is a placeholder to keep the container running if started manually. The real Spark commands are injected by the submission process. The entry point to your application (e.g., the main Python file) is still specified as an argument tospark-submit, not in the Dockerfile.
- The
Spark DataFrame
auto increment id
two ways for auto increment id
Row_number
1 | /** |
rdd.zipWithIndex
1 | // 在原Schema信息的基础上添加一列 “id”信息 |
Add constant column
1 | import org.apache.spark.sql.functions.typedLit |
select latest record
Hive Hints
PySpark
Spark Language SDKs and Internal Execution**
Spark provides APIs in Scala, Java, Python, and R. They all work by building a plan for Spark’s core engine.
- Key Clarifications on Spark Execution
- Language SDKs (PySpark / Spark Java / Spark Scala / SparkR) present the same high-level APIs and result in a language-agnostic logical plan → optimizer → physical plan.
- The physical plan is executed by Spark’s engine (the JVM executors) in the common case.
- Language-specific user code (Python UDFs, R UDFs, etc.) runs outside the JVM and requires data to be serialized/deserialized between JVM and the language runtime.
- Language Comparison:
- Scala/Java: Offer the best performance as they run natively on the JVM, the same as Spark itself.
- Python (PySpark): Easiest to use and has a massive data science ecosystem. It’s the most common choice for new projects.
- How Spark Executes Code (The “Plan”):
- Your code (in any language) builds a language-agnostic Logical Plan describing the transformations you want.
- This plan is sent to Spark’s Catalyst Optimizer, which figures out the most efficient Physical Plan for execution.
- This optimized plan is then executed on the JVMs in the executor pods.
- Python is NOT Translated to Scala:
- The Spark executor (a JVM process) starts a separate Python process on the same worker node.
- For standard DataFrame operations (
select,filter,groupBy), the optimized plan runs entirely inside the high-performance JVM. - Data is only transferred from the JVM to the Python process when you call a Python User-Defined Function (UDF). This data transfer creates overhead and is why Python UDFs can be slower than their Scala/Java counterparts.
- Using Scala/Java in PySpark: You can get the best of both worlds. Write performance-critical logic in Scala/Java, package it as a JAR file, and include it in your PySpark job using the
--jarsflag inspark-submit.- For Python UDFs:
- Regular UDFs run in separate Python worker processes; Spark serializes rows (Pickle or other) to Python, executes the UDF, then serializes results back – this is the expensive path.
- Pandas UDFs (vectorized UDFs) use Apache Arrow to transfer columnar batches, vastly reducing overhead and improving throughput.
- Py4J is used for driver ⇌ JVM communication; executor side Python workers are launched by the JVM executor process (not by the driver).
- For Python UDFs:
- Practical Implications
- Prefer built-in Spark SQL functions or JVM UDFs for best performance.
- Use Pandas UDFs/Arrow for heavy Python UDF work to reduce serialization overhead.
- If you need heavy, reusable logic that must run in the JVM, implement it in Scala/Java, package as a JAR, and supply it with
--jarsor--packages; Python can call into it via SQL or registered UDFs.
context switching
When executing Python code, such as Pandas or PySpark UDFs, the related data is processed within the executor’s Python interpreter. The executor’s Python interpreter operates directly on the data available on the executor node, without the need to transfer the data back to the driver node.
This is one of the benefits of using PySpark and executing Python code within the Spark framework. The data is distributed across the worker nodes, and the Python code is executed in parallel on the executor nodes where the data resides. This avoids unnecessary data transfer between the executor nodes and the driver node, which can improve performance and reduce network overhead.
When you invoke Python code, such as a Pandas or PySpark UDF, on a Spark DataFrame, the processing happens in a distributed manner on the executor nodes. Each executor processes the corresponding subset of the data and applies the Python code to that subset independently. The results are then combined, and the final result is returned to the driver node.
It’s worth noting that the data transfer between the executor nodes and the driver node typically occurs when there is a need to exchange intermediate results, aggregate data, or perform actions that require collecting data to the driver, such as calling collect() or toPandas(). In those cases, the relevant data is transferred from the executor nodes to the driver node. However, for processing performed within the executor’s Python interpreter, the data remains on the executor node and is processed locally within the Python environment of each executor.
Within each executor process on the worker nodes, there is an instance of the Spark engine. The Spark engine is responsible for coordinating the execution of tasks, managing data partitions, optimizing query plans, and handling data distribution and parallelization.
The Spark engine within the executor process, often referred to as the “Spark Task Execution Engine,” is implemented in Java and runs within the JVM portion of the executor. It handles the coordination and execution of tasks assigned to that executor, manages data partitioning, and applies optimizations to the execution plan.
The Python interpreter within the executor process interacts with the Spark engine through a bridge, commonly known as the PySpark API or PySpark Gateway. This bridge facilitates the communication and coordination between the Python interpreter and the Spark engine. It allows the Python interpreter to send instructions and data to the Spark engine, and the Spark engine to send results and intermediate data back to the Python interpreter.
The PySpark API acts as a bridge between the Python code and the Spark engine, enabling seamless integration between Python and Spark. It allows Python code, including Pandas or PySpark UDFs, to interact with the Spark engine’s distributed computing capabilities and leverage its optimizations and parallel processing.
Through this bridge, the Python interpreter can issue Spark operations, manipulate distributed data, and coordinate with the Spark engine for task execution, data shuffling, and data serialization. The Spark engine, in turn, manages the execution plan, coordinates task execution across worker nodes, and optimizes the execution for distributed processing.
So, in summary, there is a Spark engine within each executor process on the worker nodes, and there is a bridge (PySpark API) that facilitates communication between the Python interpreter and the Spark engine within the executor process.
————–wrong????———————–
- The Python interpreter referred to in the context of PySpark is primarily associated with the driver program. The driver program runs the user code and coordinates the execution of the Spark job. It initiates the execution of tasks on the worker nodes (executors) and manages the overall workflow of the Spark application.
When a PySpark UDF is used, the UDF code itself runs within the Python interpreter on the driver. However, the data on which the UDF operates is distributed across the worker nodes. PySpark leverages a client-server architecture to transfer the necessary data from the worker nodes to the Python interpreter on the driver. This means that when the UDF is applied to a DataFrame column, the data required for computation is shipped from the executor nodes to the driver node. This movement of data incurs serialization and deserialization overhead.
When using PySpark to define a UDF, the UDF operates within the Python environment. The UDF defined in Python is not directly converted to a Scala UDF. Instead, PySpark provides a bridge between Python and the underlying Spark engine, allowing the execution of Python code within the Spark framework. The UDF is executed by the Python interpreter on the driver, and the necessary data is shipped from the executors to the driver for computation.
Let’s dive into the practices mentioned in more detail:
Use Broadcast Variables: Spark’s broadcast variables allow you to efficiently share small read-only data structures across all the tasks in a Spark job. Instead of sending the data separately to each executor, the data is broadcasted to all the nodes, reducing the need for repeated serialization and deserialization. This is particularly useful when you have small lookup tables or configuration data that is required by multiple tasks. Broadcasting such variables helps in avoiding the overhead of transferring the same data to each task individually.
Utilize Vectorized Operations: Vectorized operations refer to performing operations on entire arrays or columns of data instead of individual elements. Libraries like NumPy and Pandas provide vectorized operations, which process data in bulk using optimized low-level operations. By leveraging these libraries within PySpark, you can take advantage of efficient vectorized operations and reduce the need for individual serialization and deserialization of data. This can significantly improve performance, especially when working with large datasets.
By using broadcast variables and utilizing vectorized operations, you can optimize the performance of your PySpark applications by reducing the serialization overhead and minimizing data movement across the Python and Java/Scala runtime environments.
The bridge between Python and the underlying Spark engine is primarily established on the driver node. PySpark acts as a connector between the Python code running on the driver and the Spark engine, which is typically implemented in Scala and Java. The driver node runs the Python interpreter and coordinates the execution of Spark tasks on the executor nodes.
The Scala UDF definition/registration is sent to the executor nodes during the execution of a Spark job. When you define or register a Scala UDF, it is part of the overall job’s execution plan. When the job is submitted to Spark for execution, the plan is distributed to the worker nodes (executors). The necessary functions, including the Scala UDF, are then available on each executor to perform the required computations.
When utilizing vectorized operations with libraries like Pandas or NumPy within PySpark, it is correct that the data required for processing needs to be sent from the data nodes to the driver node. This transfer of data incurs serialization and deserialization overhead. However, vectorized operations are designed to process data in bulk, leveraging highly optimized low-level operations. This allows for efficient computation within the Python interpreter on the driver node, potentially reducing the overall processing time. It’s important to consider the trade-off between the serialization overhead and the performance gain achieved through vectorized operations. This approach is most effective when the benefits of vectorized operations outweigh the cost of data transfer between the nodes.
Certainly! Let’s walk through the end-to-end process and the components involved when a PySpark application is submitted. We’ll consider a scenario where both Spark UDFs and Python UDFs are registered and used, and Pandas is utilized to process certain columns. The example will cover the key components and steps involved in the process:
Driver Node and Application Submission:
- The driver node is a machine where the PySpark application is submitted and executed.
- The driver node runs the Python interpreter and initiates the execution of the Spark application.
Spark Context and Session:
- The Spark Context (SparkContext) is created on the driver node as the entry point to the Spark application.
- The Spark Session (SparkSession) is a higher-level API that provides a unified interface for interacting with Spark and enables DataFrame and Dataset operations.
Job Execution and Task Distribution:
- The PySpark application code, including the registration of Spark UDFs and Python UDFs, is executed on the driver node.
- The application code defines transformations and actions on Spark DataFrames or RDDs.
- Spark breaks down the transformations into a directed acyclic graph (DAG) of stages and tasks.
- The tasks are distributed across the worker nodes (executors) for parallel execution.
Data Processing:
- When a transformation or action is invoked, Spark creates a logical plan that represents the computations required.
- If a Python UDF is used, data required for processing is transferred from the executor nodes to the driver node for UDF computation.
- If a Spark UDF is used, the UDF computation occurs within the Spark engine on the executor nodes, without data transfer to the driver.
Serialization and Deserialization:
- Data serialization and deserialization occur when transferring data between the Python and Java/Scala runtime environments.
- When using Pandas to process columns, the data may need to be serialized for transfer to the driver and deserialized back into Pandas DataFrame structures.
Spark Catalyst Optimizer and Execution:
- Spark’s Catalyst optimizer analyzes the logical plan and optimizes it by applying various rule-based transformations to generate an optimized physical plan.
- The optimized physical plan is executed by the Spark engine on the executor nodes, leveraging Spark’s execution engine components such as the Task Scheduler, Shuffle Manager, and Memory Management.
Result Aggregation and Return:
- The results of transformations and actions are aggregated and returned to the driver node.
- If required, Pandas can be used to process the result data on the driver node, leveraging its functionality for further analysis or visualization.
It’s important to note that the components and steps involved can vary depending on the specifics of the PySpark application and the cluster configuration. The example provided highlights the major components and steps, focusing on the interactions between the driver node, executor nodes, and data transfer between Python and Java/Scala environments.
—————-wrong????——————
pyspark udf vs scala udf
Certainly! Let’s delve into the performance aspect of using UDFs defined in Scala versus PySpark in more detail:
Execution Engine Integration: Scala UDFs have a closer integration with Spark’s execution engine since Scala is the native language for Spark. This tight integration allows Scala UDFs to leverage Spark’s Catalyst optimizer and take advantage of advanced query optimization techniques. This can potentially lead to better query planning and execution, resulting in improved performance.
Serialization and Deserialization Overhead: When using PySpark UDFs, data must be serialized and deserialized between the Python and Java/Scala runtime environments. This incurs additional overhead and can impact performance, especially when working with large datasets. In contrast, Scala UDFs avoid this serialization overhead since they operate directly within the Spark engine.
JIT Compilation: Scala benefits from just-in-time (JIT) compilation provided by the Java Virtual Machine (JVM). This means that Scala UDFs can be optimized at runtime, potentially resulting in better performance. In contrast, Python code executed within PySpark does not have the same level of JIT compilation, which can lead to slower execution.
Data Movement and Shuffling: Both Scala and PySpark UDFs may involve data movement and shuffling operations, which can impact performance. However, since Scala UDFs have a closer integration with Spark’s execution engine, they may enable more efficient data processing and minimize data shuffling, leading to better performance in certain scenarios.
It’s important to note that the performance impact of using UDFs can vary depending on the specific workload, data size, and operations performed. In some cases, the overhead introduced by PySpark UDFs may not be significant, especially if the UDFs themselves are not the main bottleneck in the application. Additionally, other factors such as cluster configuration, data skew, and overall data processing pipeline design can also influence performance.
To determine the performance implications of using UDFs, it’s recommended to benchmark and profile your specific Spark application using both Scala and PySpark implementations. This will provide insights into the actual performance differences and help you make an informed decision based on your specific requirements and constraints.
Arrow
Apache Arrow in PySpark 3.4.1 documentation
Optimization
deep dive - spark optimization
Get Baseline
- 利用 spark-ui 观察任务运行情况(long stages,spill,laggard tasks, etc.)
- 利用 yarn 等观察资源利用情况(CPU 利用率 etc.)
Memory spill
Spark 运行时会分配一定的 memory(可以指定资源需求), 分 storage 和 working memory。
- storage memory 是 persist 会用的 memory。当调用 persist(或 cache,一种使用
StorageLevel.MemoryAndDisk的 persist)时,如果指定的 storage_level 有 memory,那么就会将数据存到 memory。 - working memory 是 spark 运算所需要的 memory,这个大小是动态变化的。当 storage memory 占用过多内存时,working memory 就不够了。然后就会有 spill,就会慢。
memory spill 表示 working memory 不够,spark 开始使用 disk。而 disk 的 I/O 效率是极低的。所以一旦出现 spill,性能就会大大降低。
working memory 不够有很多原因:
- Memory 资源申请的太少了,就是不够 ====》 增加
spark.executor.memory- 数据在 memory/disk 的存储一般是 serialized,以节省空间。但数据 load 到 working memory 时,一般都是 deserialized 的,处理更快,但是更占空间。
- 资源可以了,partition 太少,每个 partition 处理的数据太多,所以 spill 了 ====》 增加 shuffle partition
- 有不均衡出现,导致某些 task 处理的数据尤其多 ====》see balance
- 有太多 persist,持久化了太多东西,占用过多的 storage memory ====》see persistence
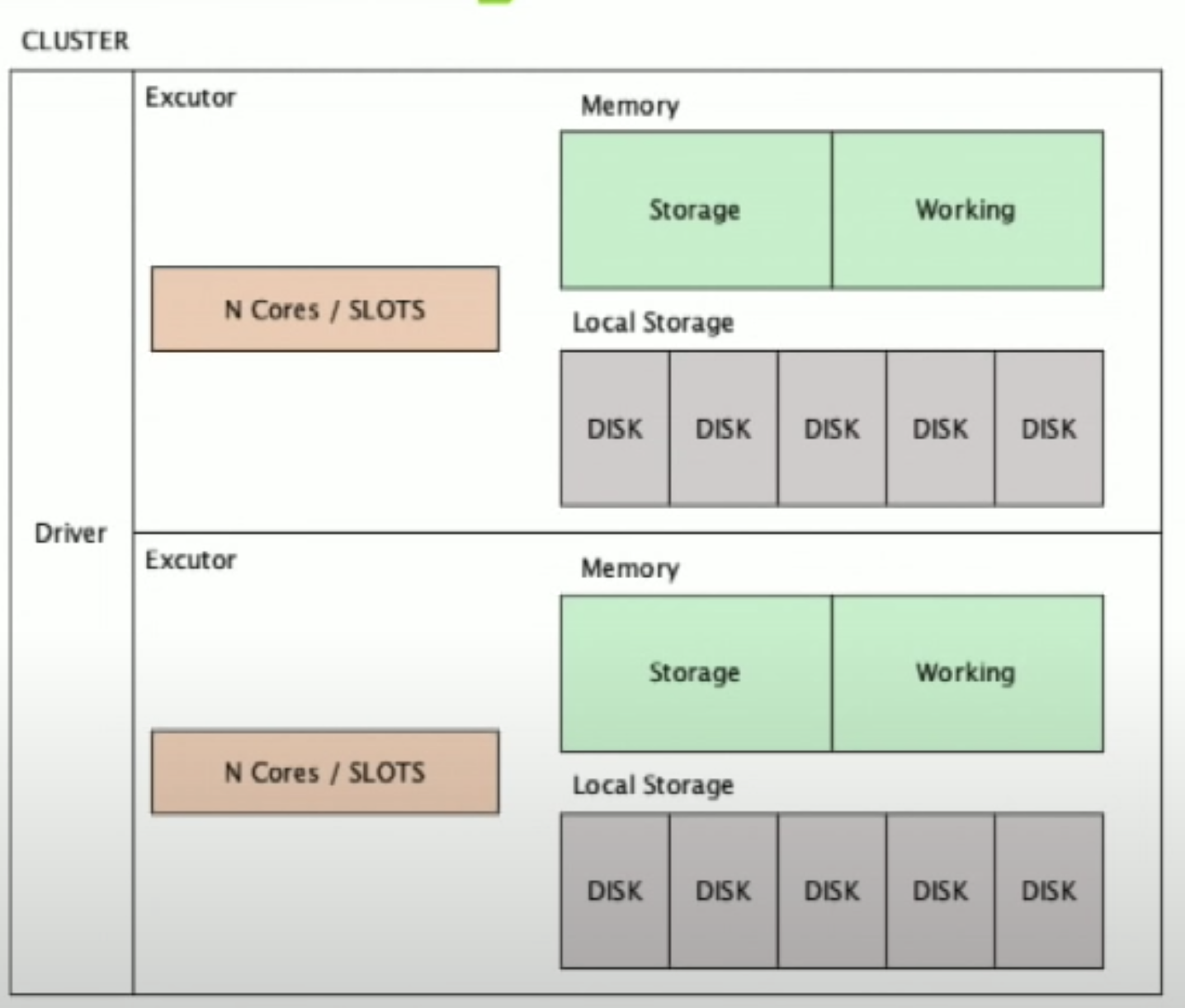

指定资源需求
Spark-submit 运行时,可通过指定以下参数来定义运行所需的资源:
--conf spark.num.executors=xx(或--num-executors xx):指定运行时需要几个 executor(也可以通过 dynamic allocation 来根据运算动态分配 executors)--conf spark.executor.memory=xxG(或--executor-memory xxG):指定每个 executor 所需要的内存--conf spark.executor.cores=xx(或--executor-cores xx):指定每个 executor 所需要的 cores--conf spark.driver.memory=xxG(或--driver-memory xxG):指定每个 driver 所需要的内存。当执行df.collect()时,会将数据 collect 到 driver,此时就需要 driver 有很多的 memory--conf spark.driver.cores=xx(或--driver-cores xx):指定每个 driver 所需要的 cores
Some issues
–executor-cores settinng not working
需要配置 yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator,因为默认的使用的是 DefaultResourceCalculator,它只看 memory(–executor-memory),DominantResourceCalculator 则同时考虑 cpu 和 memory
see stackoverflow
–spark.dynamicAllocation.maxExecutors not working
这个需要和其他配置配合使用
spark.dynamicAllocation.enabled = true
This requiresspark.shuffle.service.enabledorspark.dynamicAllocation.shuffleTracking.enabledto be set. The following configurations are also relevant:spark.dynamicAllocation.minExecutors,spark.dynamicAllocation.maxExecutors, andspark.dynamicAllocation.initialExecutorsspark.dynamicAllocation.executorAllocationRatio
如果还不工作,可能要按 [spark dynamic allocation not working](https://community.cloudera.com/t5/Support-Questions/Spark-dynamic-allocation-dont-work/td-p/140227 设置各 nodemanager 并重启
Partitions
接下来从输入、运行、输出三个阶段的 partition 优化来看
一般 1 partition -> 1 task,分多少个 partition,就拆多少个 task 来运行。
- Avoid the spills
- Maximize parallelism
- utilize all cores
- provision only the cores you need
输入(input)
1 | spark.default.parallelism (don't use) |
Shuffle
1 | spark.sql.shuffle.partitions(控制使用多少个 partition 来 shuffle) |
如果配置了 spark.conf.set("spark.sql.adaptive.enabled", 'true') 或 spark.sql.adaptive.coalescePartitions.enabled ,它会动态控制 parition count (参见 coalescing post shuffle partitions),根据 shuffle 数据大小来动态设置 partition 数目。但是这个设置可能不合理,因为 shuffle 过程中,最终操作的数据可能远大于 shuffle read 的大小,这个过程中存在 deserialize 等。如果配置了动态控制,依然出现了 shuffle spill,那么可以先关掉这个配置,手动控制 shuffle partitions 大小。
输出(output)
1 | coalesce |
Balance
When some partitions are significantly larger than most, there is skew.
Balance 体现在很多方面:网络、GC、数据,当然最常见的问题是数据的不均匀。
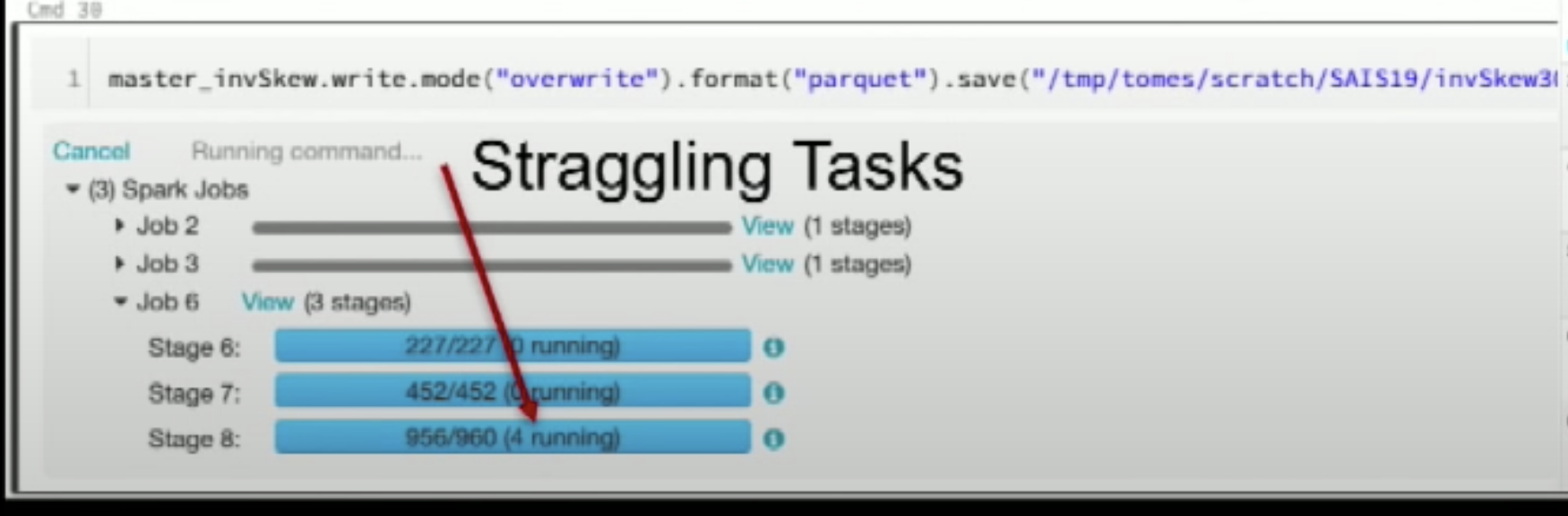
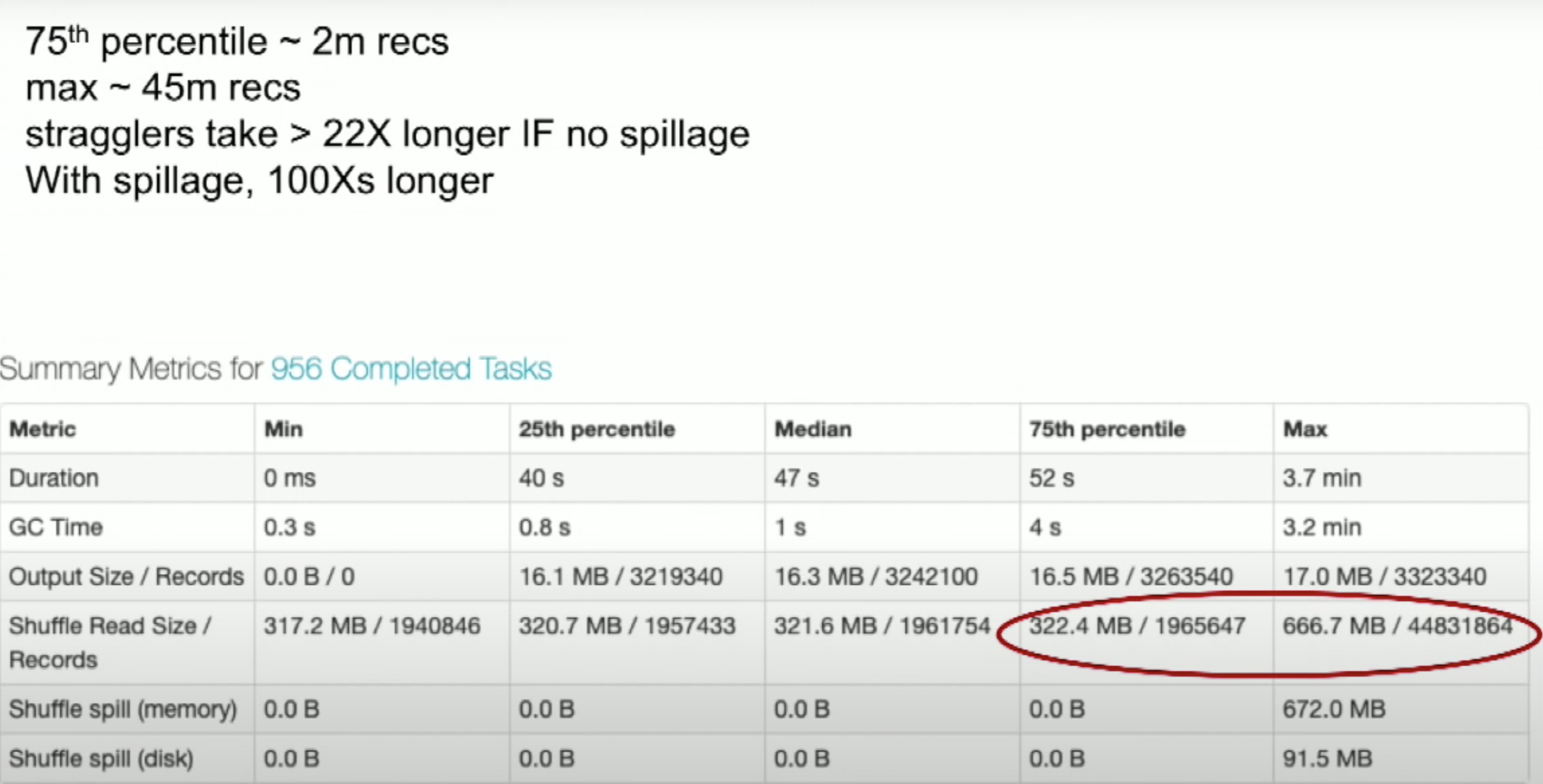
通过查看 spark ui 可以看到不均匀的任务(这个时候需要停掉重跑):
- 查看 straggling tasks
- 查看 stage 执行进度:stage 里剩余几个 task 执行特别慢,这个时候各个 task 处理的数据肯定存在不均匀,导致那几个 task 处理的尤其慢
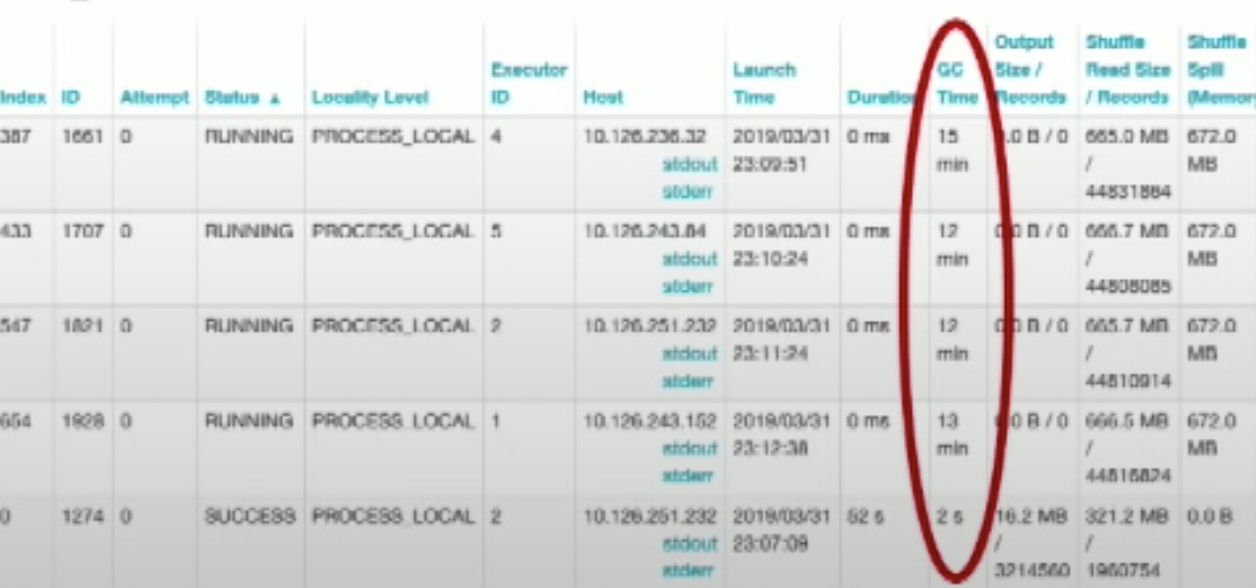
- 查看 stage 执行 metric:大部分时候没有 spill,但是 max 的时候有 spill;或者大部分的时候 read size 和 max read size 有很大差别
- 查看 stage 执行进度:stage 里剩余几个 task 执行特别慢,这个时候各个 task 处理的数据肯定存在不均匀,导致那几个 task 处理的尤其慢
- 查看 stage 里各个节点的 GC time,GC time 分布不均匀,也是有问题的(什么问题??)
Persistence
当 execution plan 中,有些 superset 被多个 subset 所使用,superset 计算复杂、耗时久,这个时候就可以选择将 superset persist,从而避免重复运算。
spark core 中有几个概念,其中只有 action 会触发一次 dag 的运行。同一段代码,可能会生成不同的 dag,每次都需要执行。所以如果被多次使用的 superset,最好将它 cache,避免后续的重复运算。
persist/cache 要慎用,因为:
- 占资源。当 persist 消耗了太多的 storage memory 时,就会出现 memory spill
- 也有时间损耗(serialize, deserialize, I/O)。persist 一般都以 serialized 的形式存储,节省空间,而 load 到 working memory 时,又需要 deserialiize
In Python, stored objects will always be serialized with the Pickle library, so it does not matter whether you choose a serialized level. The available storage levels in Python include
MEMORY_ONLY,MEMORY_ONLY_2,MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY,DISK_ONLY_2, andDISK_ONLY_3.*
cache
Cache 是选择 default 的 persist。persist 可以选择不同的 persistence storage level
With cache(), you use only the default storage level :
MEMORY_ONLYfor RDDMEMORY_AND_DISKfor Dataset
With persist(), you can specify which storage level you want for both RDD and Dataset.
From the official docs:
- You can mark an
RDDto be persisted using thepersist() orcache() methods on it.- each persisted
RDDcan be stored using a differentstorage level- The
cache() method is a shorthand for using the default storage level, which isStorageLevel.MEMORY_ONLY(store deserialized objects in memory).
Use persist() if you want to assign a storage level other than :
MEMORY_ONLYto the RDD- or
MEMORY_AND_DISKfor Dataset
1 | spark.catalog.cacheTable("tableName") |
broadcast join
几种方式:
1. spark 自动识别小表 broadcast
spark.sql.statistics.fallBackToHdfs=True, 这样它会直接分析文件的大小,而不是 metastore 数据
2. 使用 hint
1 | select /*+ BROADCAST (b) */ * from a where id not in (select id from b) |
3. 使用 dataframe api
1 | from pyspark.sql.functions import broadcast |
cache vs broadcast
RDDs are divided into partitions. These partitions themselves act as an immutable subset of the entire RDD. When Spark executes each stage of the graph, each partition gets sent to a worker which operates on the subset of the data. In turn, each worker can cache the data if the RDD needs to be re-iterated.
Broadcast variables are used to send some immutable state once to each worker. You use them when you want a local copy of a variable.
These two operations are quite different from each other, and each one represents a solution to a different problem.
小文件问题
On Spark, Hive, and Small Files: An In-Depth Look at Spark Partitioning Strategies
为什么会有小文件?
当 spark 要 write 到 hive 表时,这实际也是一个 shuffle stage,就会分很多个 sPartition (spark partition)。每个 sPartition 在处理时,都会生成一个文件(如果是动态分区,则更严重,因为每个 sPartition 的数据分布式均匀的,每个 sPartition 可能包含很多个 hive paritition key,spark 每遇到一个 partition key 就生成一个文件),那么 sPartition 数目越多(动态分区的情况下,会更不可控),文件数就会越多。
简单来说,就是 spark 的一个 stage 分成了很多个 task(shuffle partitions 控制这个数量),即 sPartition,每个 sPartition 可能对应多个 hPartitiion(hive partition)key,多个 sPartition 也对应一个 hPartition key。而每个 sPartition 里对应的每个 hPartition key,都会生成一个文件。
那么,如果一个 sPartition 和 hPartition 只是一个 多(可控数目,对应最后每个 hPartitiion 的文件数)对一 的情况,那么文件数就是可控的。
使用 hive 时,不会有小文件问题。hive 里只需要设置下边的这些参数,就
In pure Hive pipelines, there are configurations provided to automatically collect results into reasonably sized files, nearly transparently from the perspective of the developer, such as hive.merge.smallfiles.avgsize, or hive.merge.size.per.task.
解决方案
- coalesce
- repartition
- Distribute by
- adaptive execution
Adaptive Execution 让 Spark SQL 更高效更智能
1 | # 启用 Adaptive Execution ,从而启用自动设置 Shuffle Reducer 特性 |
python udf vs scala udf
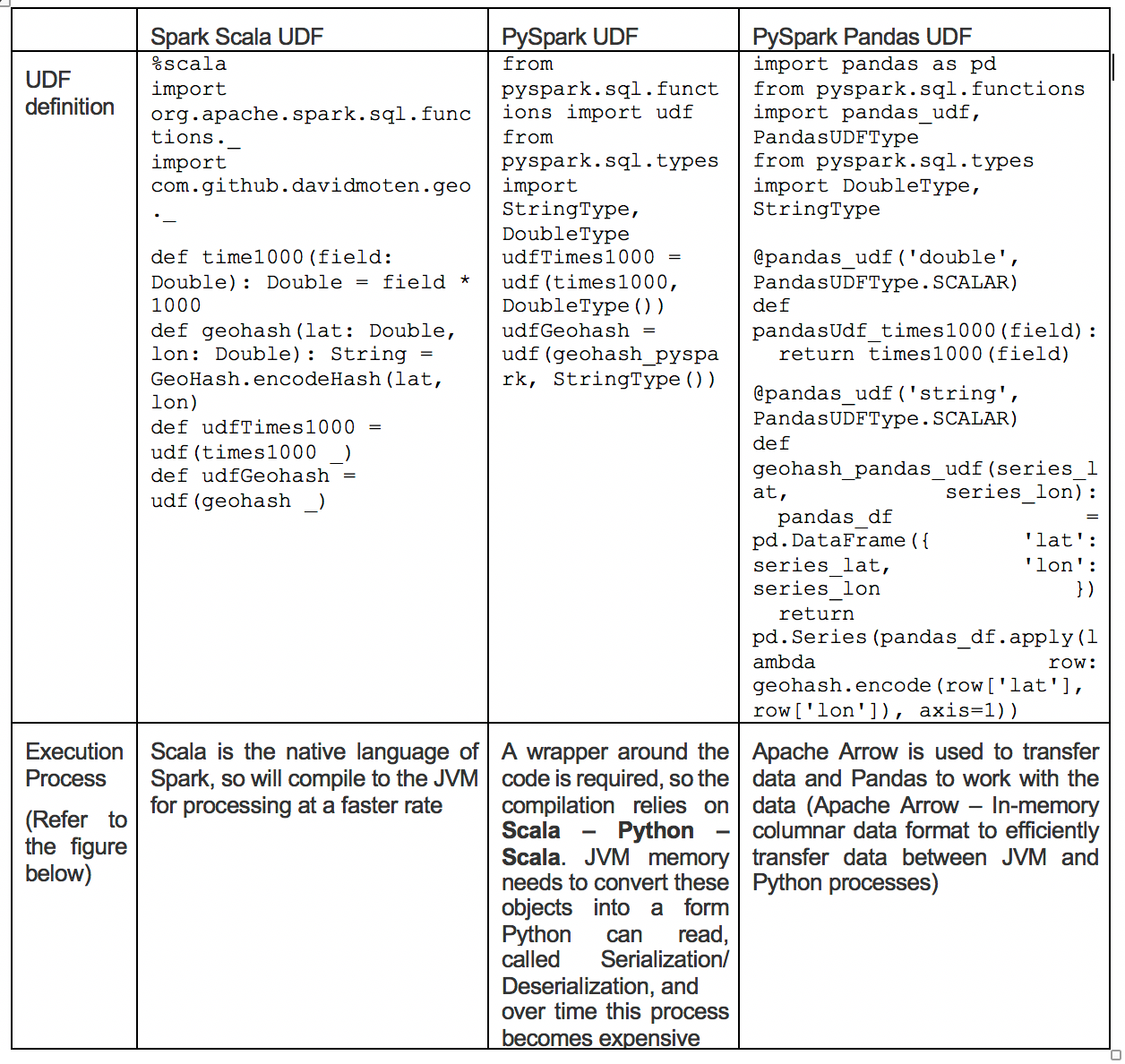
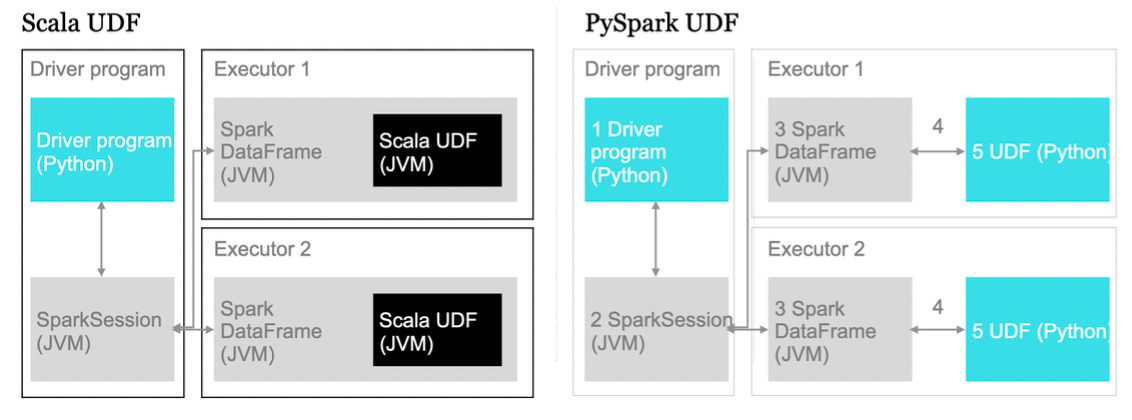
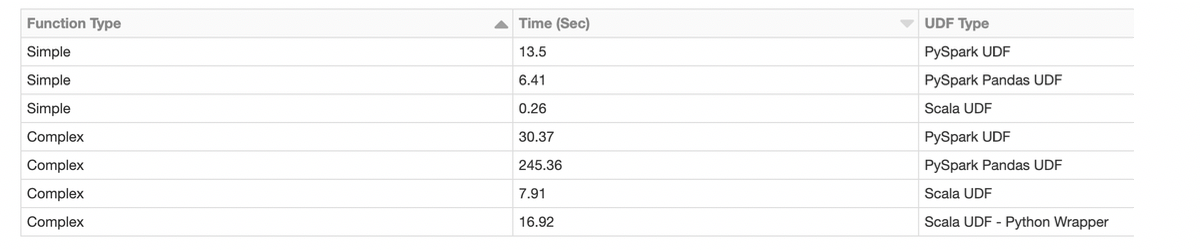
Issues
Null-aware predicate sub-queries cannot be used in nested conditions
not in 不能和 or 之类的 condition 一块用。现在好像还没有修复,参见:SPARK-25154
References
Apache Spark Documentation: The official documentation for Apache Spark is an excellent resource to understand Spark’s concepts, APIs, and optimization techniques. It includes a Quick Start guide and in-depth documentation on Spark’s features and optimizations.
Hadoop Definitive Guide: Although this is a book, it is freely available online. “Hadoop: The Definitive Guide” by Tom White provides a comprehensive understanding of Hadoop and its ecosystem. It covers various optimization techniques and best practices for managing Hadoop clusters.
YouTube Tutorials:
- Simplilearn’s Spark Tutorial: Simplilearn offers a comprehensive Spark tutorial series on YouTube, covering various aspects of Spark programming, optimization, and cluster management.
- Hadoop Tutorials by edureka!: edureka! provides a playlist of Hadoop tutorials on YouTube that cover the basics of Hadoop, including optimization and cluster management topics.
Apache Hadoop YouTube Channel: The official Apache Hadoop YouTube channel hosts a collection of videos covering different topics related to Hadoop. You can find videos on optimization techniques, cluster management, and other Hadoop-related aspects.
Hortonworks Community Connection (HCC): Hortonworks Community Connection is a platform where Hadoop enthusiasts share knowledge and resources. It includes articles, tutorials, and videos related to Hadoop optimization and cluster management. You can explore the HCC website to find relevant resources.