hdfs
hdfs architecture
HDFS 集群以 master-slave 模型运行。其中有两种节点:
- namenode: master node. know where the files are to find in hdfs
- datanode: slave node: have the data of the files
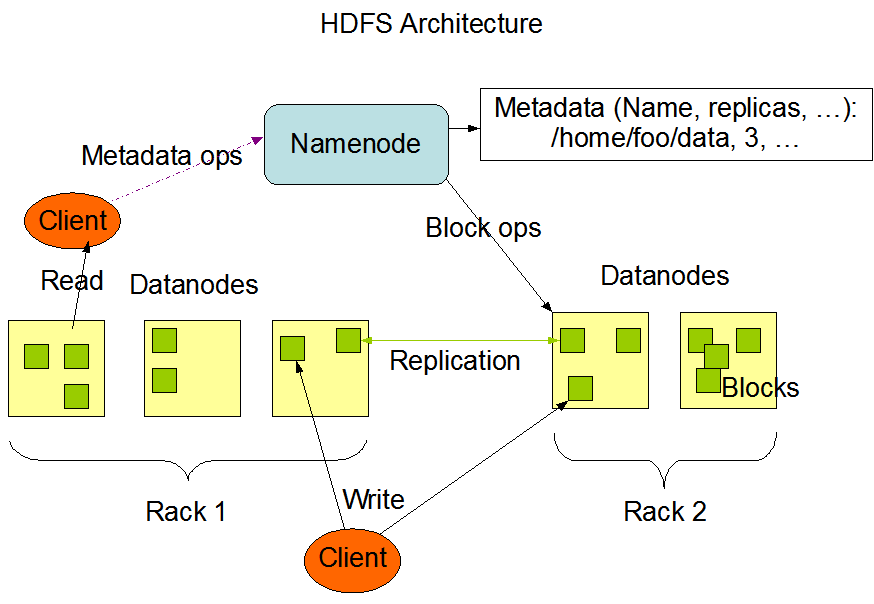
namenode
Namenode 管理着文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块 (block) 所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。

每个 file 有多个 block 构成,这些 block 分散的存储在各个 datanode 上(并且根据 replication factor,有冗余副本),而 namenode 知道如何一个 file 有哪些 block (file 的元数据信息),根据 datanode 发送给它的 block 列表,namenode 就可以构建每个文件中各个 block 的位置信息。即根据文件元数据 + datanode block 列表,可以重建文件 block 位置信息,因此不需要持久化。
容错机制
由于 datanode 只是分布式地存储 block,不知道这些 block 是怎么组织成文件,以及文件是怎么组织成文件树的。因此 namenode 一旦当掉,整个文件系统就挂了(没办法写和查文件)。因此 namenode 的容错机制很重要。常见的方式:
- 同步备份。即 namenode 中需要持久化存储的镜像文件和log,同步地持久化存储到其他文件系统中。
- secondary namenode (异步)。secondary namenode 一般定期地去同步本地 namenode 的镜像和 log。但除此之外,secondary namenode 还有其他用途,比如合并镜像和log(避免文件过大),这个合并过程很占用 cpu 和内存,所以正好在 secondary namenode 上做。合并完后,在 secondary namenode 上也保存一份。不过这种备份恢复会丢掉一部分数据。
datanode
datanode 根据客户端或者 namenode 调度存储/检索数据,并定期向 namenode 发送它们所存储的 block 列表。
commands
hdfs namenode -format
Remove all metadata in namenode. Initialize the namenode. However, the data in datanode is not removed.
hdfs dfs -mkdir xxx
Create a directory. To see the data location, see local storage
hdfs dfs -put source dest
copy content in source to dest
hdfs dfs -get
hdfs dfs -du -h -v
It displays sizes of files and directories contained in the given directory or the length of a file in case it’s just a file.
- The -s option will result in an aggregate summary of file lengths being displayed, rather than the individual files. Without the -s option, the calculation is done by going 1-level deep from the given path.
- The -h option will format file sizes in a human-readable fashion (e.g 64.0m instead of 67108864)
- The -v option will display the names of columns as a header line.
- The -x option will exclude snapshots from the result calculation. Without the -x option (default), the result is always calculated from all INodes, including all snapshots under the given path.
hadoop fs -count -h /dir/*
显示文件夹下的所有文件数、大小
web ui
hdfs default ports are changed. see here
Namenode ports: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820
Secondary NN ports: 50091 –> 9869, 50090 –> 9868
Datanode ports: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 –> 9864
local storage
From localhost:9870, you can get the namenode information. To see the data you created locally:
- Login localhost:9870, get the ‘configuration‘ from the ‘utilities‘
- Find
dfs.datanode.data.dirto get the data location
Issue: Permission denied: user=dr.who
When ‘browse the file system‘ from ‘utilities‘, there are some dirs (e.g. /tmp) you have no permission to access. It may show:
1 | Permission denied: user=dr.who, access=READ_EXECUTE, inode="/tmp":cherish:supergroup:drwx------ |
The ‘dr.who‘ is just a configured static user in core-default.xml:
1 | hadoop.http.staticuser.user=dr.who |
And there is permission check because it’s set to check by default in hdfs-default.xml:
1 | dfs.permissions.enabled=true |
There are three ways to solve it:
solutions
disable the permission check
This is not recommended in the prod mode.
Add the following property in hdfs-site.xml
1 | <property> |
change the staticuser
Add the following property in core-site.xml
1 | <property> |
modify the file permission
1 | $ hdfs dfs -chmod -R 755 /tmp |