hadoop
Hadoop is a framework of distributed storage & computing.
- distributed storage: hadoop use HDFS to save large amount of data in cluster.
- distributed computing: hadoop use map-reduce framework to conduct fast data analysis (query & writing) over data in HDFS.
- resource manager & job schedular: hadoop use yarn to manage/allocate cluster resources (memory, cpu, etc.) and to schedule and moniter job executing.
Architecture
cluster architecture
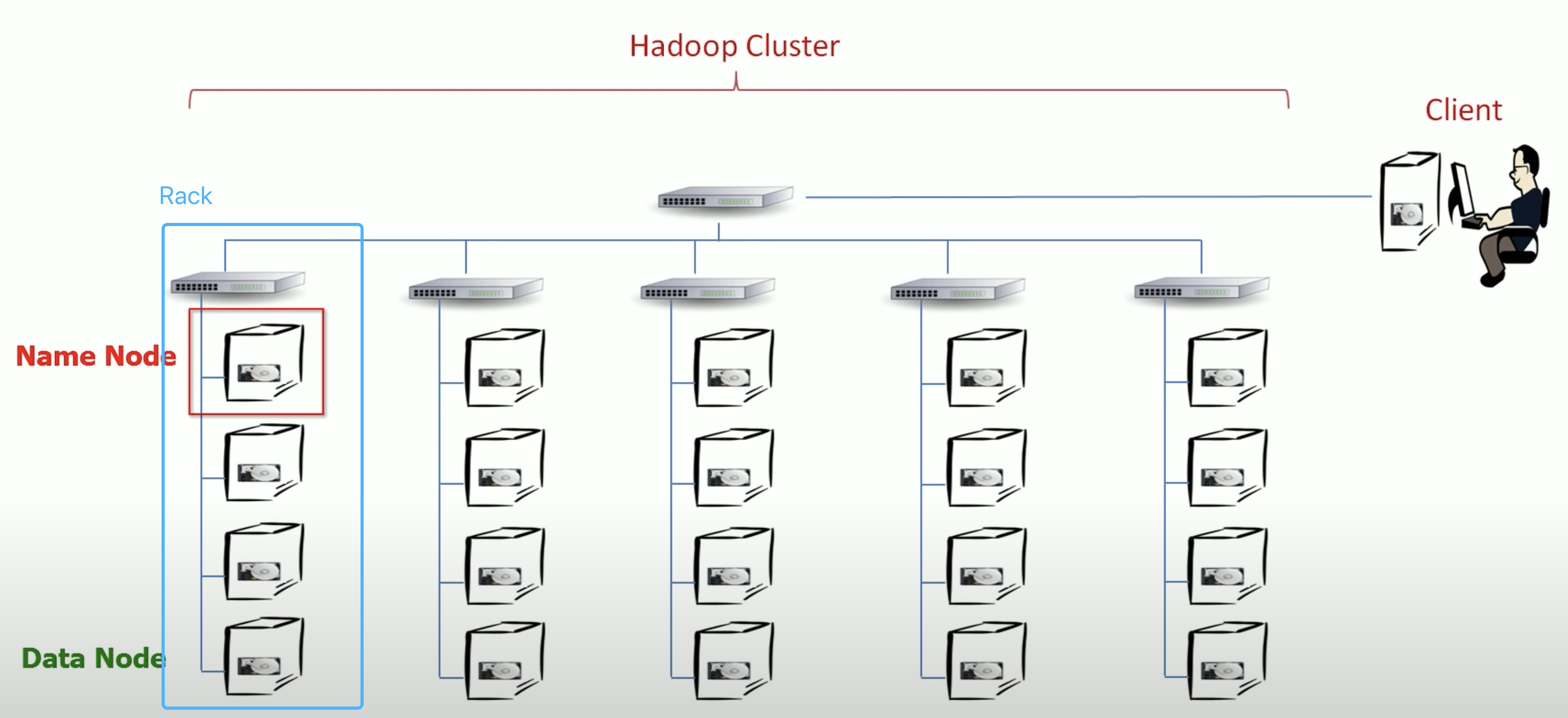

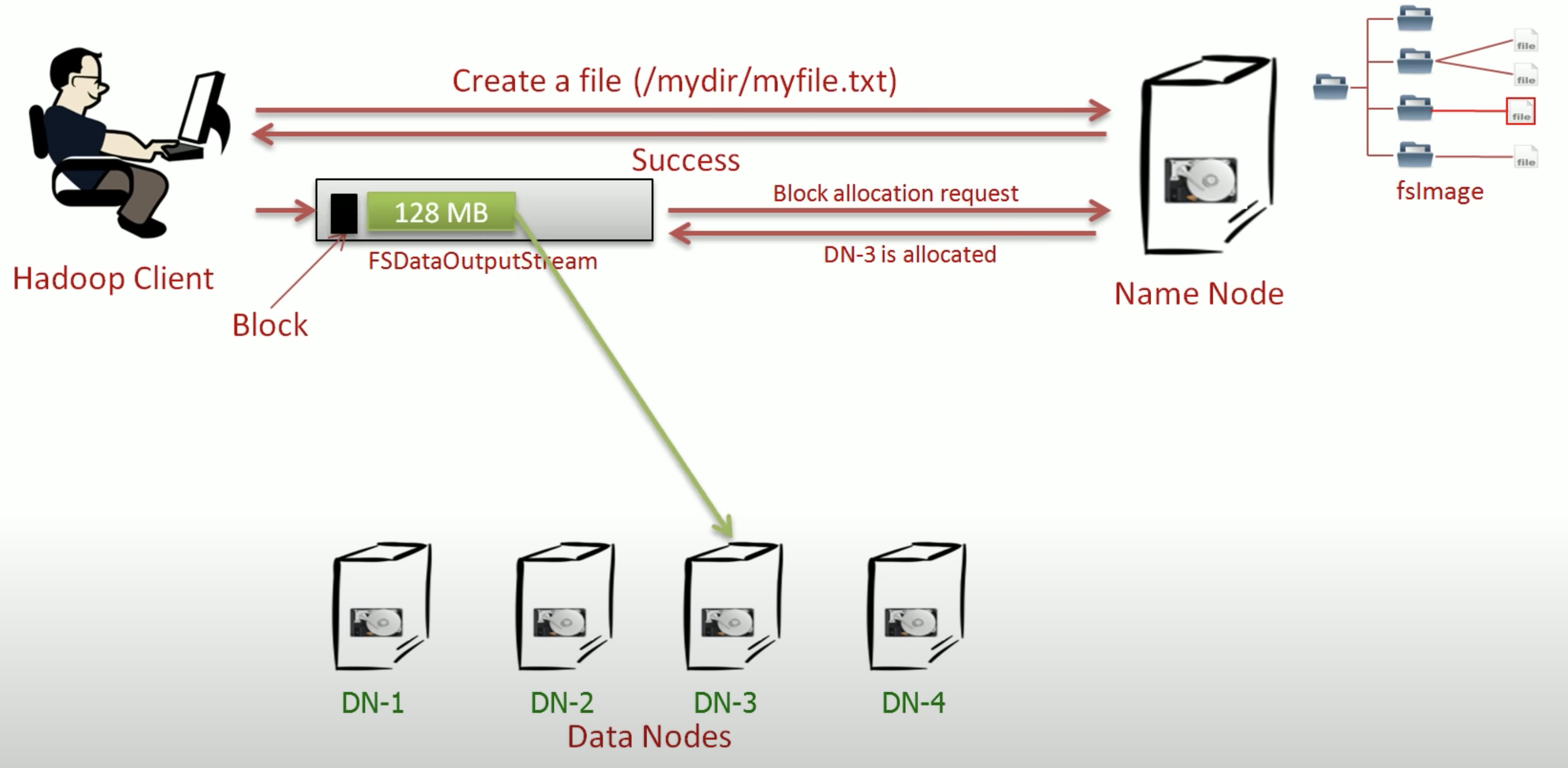
request processing
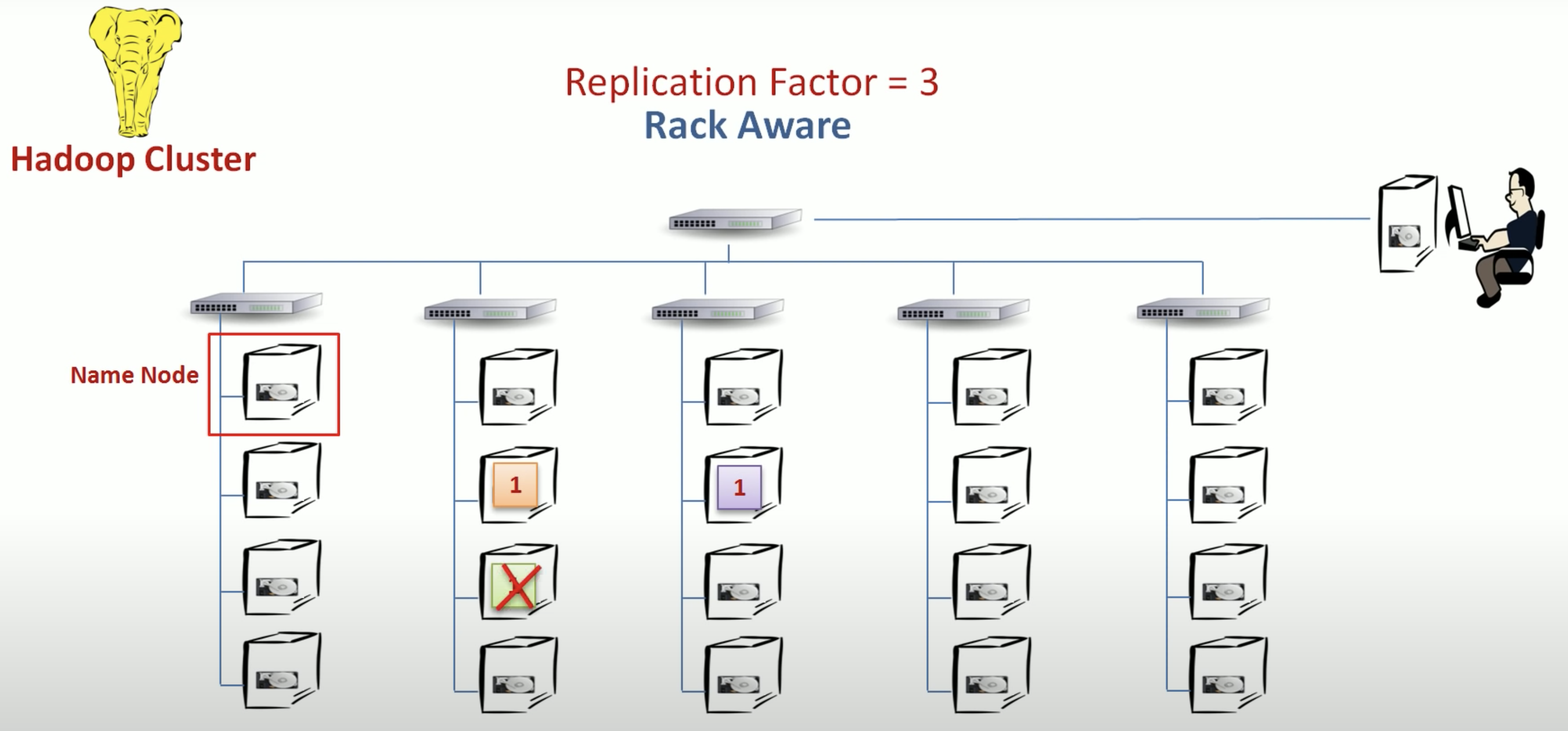
Fault Tolerance
Use rack aware so that your replicas will be saved into different racks, which can solve the rack failure issue.
Each data node will send heartbeat and block report to the namenode. Thus when data node fails, the name node knows it and will re-replicated to 3.
High Availability
High Availability: Percentage of Uptime of the system. Fault Tolerance, on the other hand, mainly focus on the data loss / system un-recovered damage tolerance. For example, a name-node failure can be processed by reboot from the aspect of fault-tolerance, while there must be a quick working solution from the aspect of high availability.
Name Node Failure
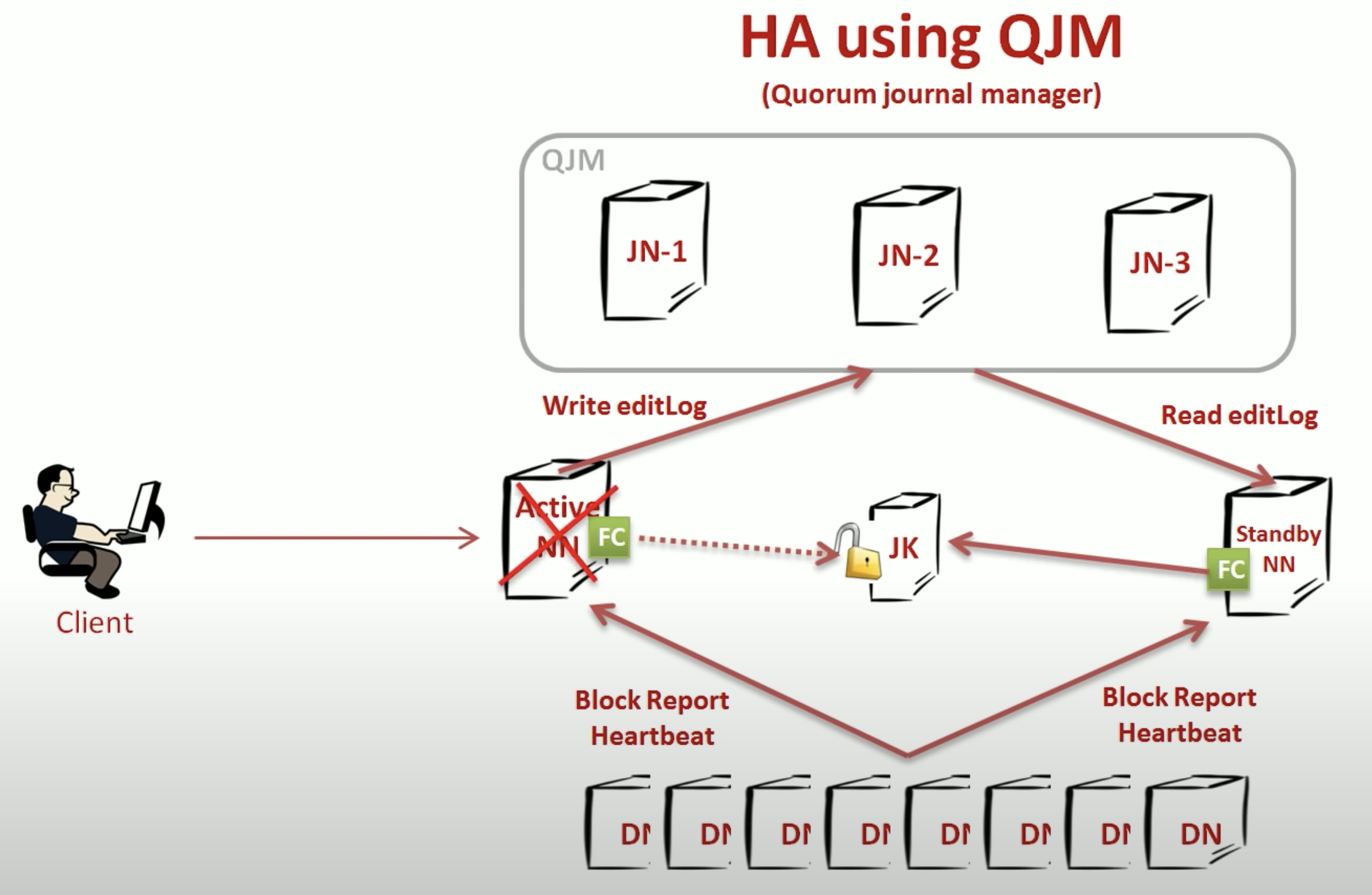
For a name node failure, we want to switch to a standby name node with all the informations quickly. How?
A name node saves the file namespaces in memory, besides, it also saved editlog for each change into the disk. A name node failure will lose the in-memory fsImage, but we can reproduce the fsImage from the editlogs
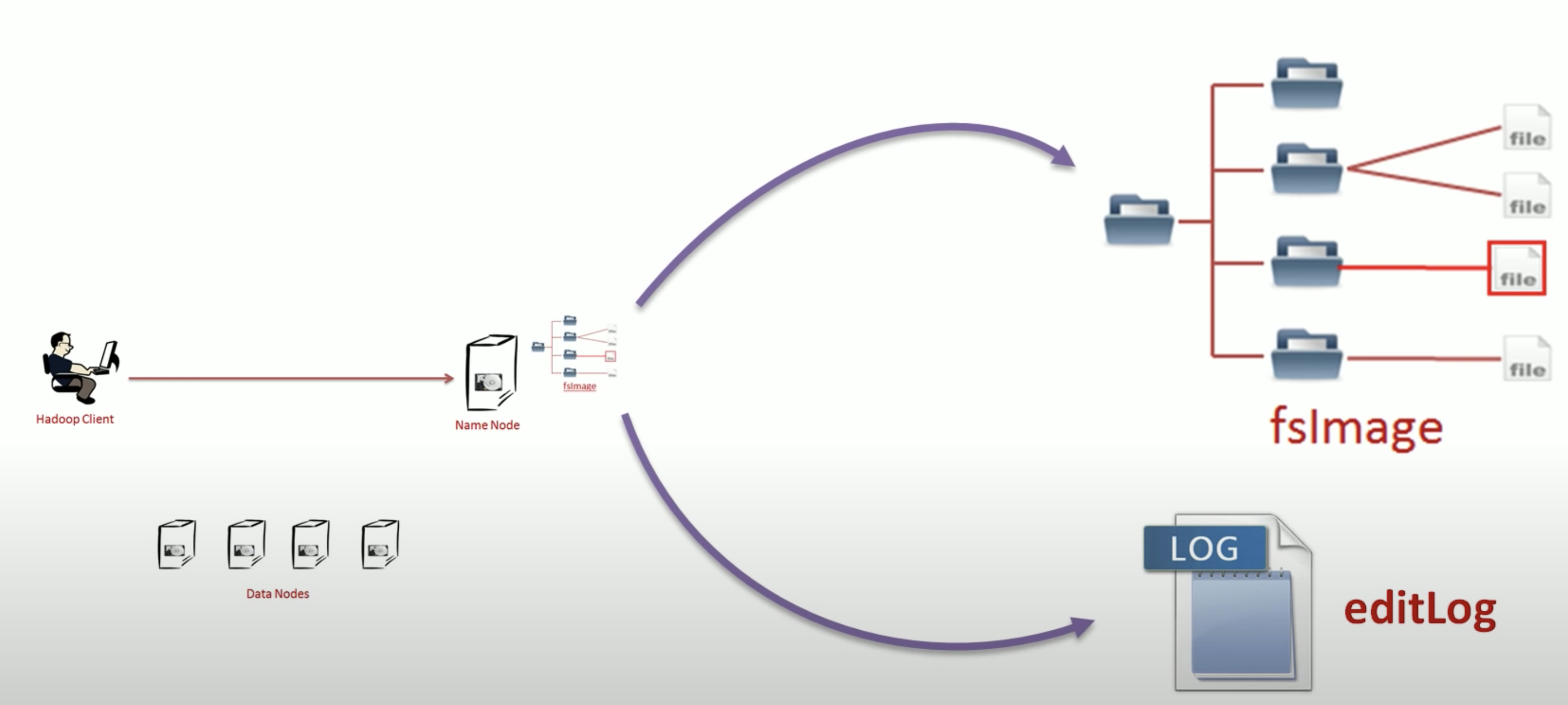
A common solution is to use QJM to save the editlogs. And the standby name node will read from the editlogs to rebuild the fsImage. Besides, there’s two failover controllers on each name node and a zookeeper. ZooKeeper keeps a lock, and both name nodes are requesting the lock. When the active name node fails, it lost the lock, and the standby nn will acquire the lock.
Name Node Reboot
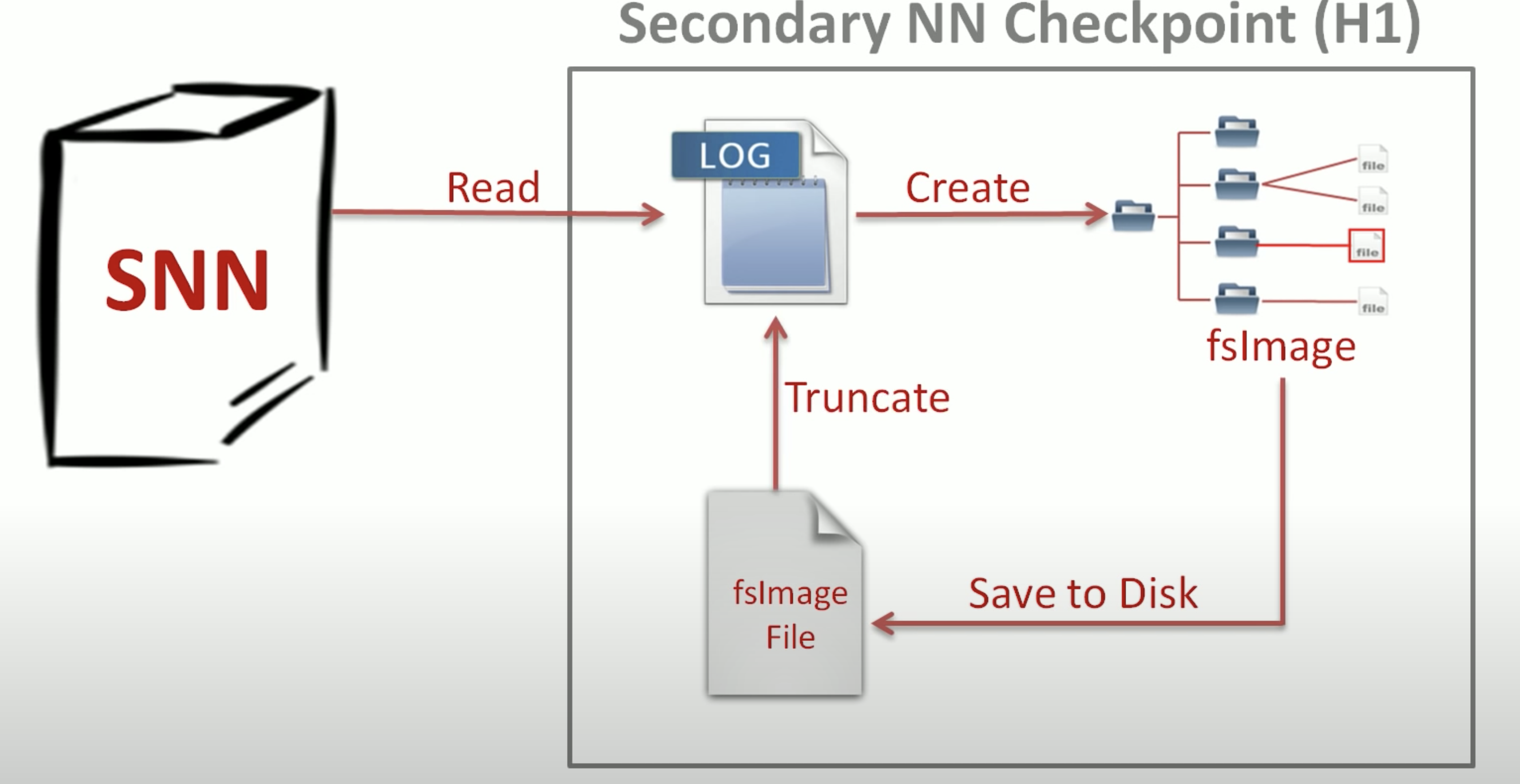
What if you just want to reboot the name node, and since the fsImage is in memory, it will be gone at once and it takes a long time to rebuild from the editlogs?
The main issue here is that the fsImage is in memory. Thus to reboot quickly, we need to save the fsImage into disk. The secondary name node is for this. It periodically merge the old fsImage with the editlogs, and replace the old fsImage in the disk, and then truncate the logs.
Secondary Name Node is not necessary. If needed, you can build it on the standby nn.
install hadoop on mac
see default ports used by hadoop services 3.1.0
when config password-free login by ssh, it may only work when generate key into id_rsa/id_dsa. The other user defind key file name won’t work.
- access hdfs
hdfs default ports are changed. see hdfs issue, or check the dfs.namenode.http-address property in hdfs-default.xml for the newest setting.
Namenode ports: 50470 –> 9871, 50070 –> 9870, 8020 –> 9820
Secondary NN ports: 50091 –> 9869, 50090 –> 9868
Datanode ports: 50020 –> 9867, 50010 –> 9866, 50475 –> 9865, 50075 – >9864
When running the example, it seems that jar can only search files. Thus you need to ensure there’s no sub-dirs in search dir.
- access yarn
Access resource manager through localhost:8088. Or check the property yarn.resourcemanager.webapp.address in yarn-default.xml for the newest configuration
start hadoop locally
map reduce is a framework to write applications which process vast amounts of data in-parallel on large clusters.
A map-reduce job usually splits the input data into independent chunks, and map in a parallel manner. Then the frameworks sorts the output and then reduce to the integrate output.
1 | # initialize the namenode |
Note:
The
hdfs namenode -formatcommand must be executed everytime you restarted your computer. And it’s initialized again. Need to figure out other ways to avoid this.
There are other commands used to start these daemon:
1 | # deprecated to use the above |