hive introduction
apache hive 是一个 data warehouse 应用。支持分布式存储的大数据读、写和管理,并且支持使用标准的 SQL 语法查询。Hive is not a database. This is to make use of SQL capabilities by defining a metadata to the files in HDFS. Long story short, it brings the possibility to query the hdfs file.
hive 并没有固定的数据存储方式。自带的是 csv(comma-separated value)和 tsv (tab-separated values) connectors,也可以使用 connector for other formats。
database v.s. warehouse
参见 the difference between database and data warehouse
database:
存储具体的业务数据,完善支持 concurrent transaction 操作(CRUD)。
database contains highly detailed data as well as a detailed relational views. Tables are normalized to achieve efficient storage, concurrent transaction processing, as well as return quick query results.
- **主要用于 OLTP (online trancaction processing)**。
- use a normalized structure. 即通常会组织成 table、row、column,冗余信息很少(比如三张表 product、color、product-color),所以节省空间。在查询时就需要通过复杂的 join 来实现,所以分析性的查询会比较耗时
- no historical data. 主要处理 transaction 数据,只保存现在的数据,进行的查询和分析也是基于现有数据。即它的分析是 static one-time reports
- optimization 主要是优化写速度、读速度。复杂分析因为涉及很多 join,其性能提升也是一个主要的问题。
- 经常需要满足关系型数据库的 ACID 原则(atomicity, consistency, isolation, and durability)。所以它需要支持并发操作下的数据完整性。对 concurrent transaction 的支持要求比较高。
data warehouse
将企业中的各种数据收集起来,重新组织,对这些数据做高效 分析
A data warehouse is a system that pulls together data from many different sources within an organization for reporting and analysis. The reports created from complex queries within a data warehouse are used to make business decisions.
The primary focus of a data warehouse is to provide a correlation between data from existing systems, i.e., product inventory stored in one system, purchase orders for a specific customer, stored in another system. Data warehouses are used for online analytical processing (OLAP), which uses complex queries to analyze rather than process transactions.
- 主要用于 OLAP (online analysis processing). 它收集企业内各个数据源的数据,建立数据关联,对这些数据做复杂的查询分析,以辅佐业务决策。
- use a denormalized structure. 它收集多个相关数据源的数据,将这些 table denormailize、transform,获得 summarized data、multidimentional views,并基于这些数据实现快速分析和查询。它不在乎冗余,相反,很多时候正是通过冗余重新组织数据,使得查询更方便。
- store historical data. data warehouse 主要是用于分析的,所以通常会存储历史数据,以实现对历史数据和现有数据的对比分析。
- optimization 主要是查询响应速度。它对大数据做分析,响应速度是主要的衡量标准。
- 一般不支持高并发操作。支持一定并发,但支持程度远不如 database
installation
See hadoop: setting up a single-node cluster, GettingStarted
Hive relies on hadoop. And we need a db (eg. mysql) to store hive metadata. So the prerequisites are:
- hadoop installed
- mysql installed: to store hive metadata
- java installed: ??
- ssh installed and sshd running: when running hadoop scripts and managing remote hadoop daemons, it use ssh to authenticate.
install hadoop on mac
install hive on mac
After init mysql, you may find that you can’t connect mysql using ‘-uhive -pxxx’. Then try to grant privileges to
'hive'@'%'instead of'hive'@'localhost'. Use wildcard%to match all hosts.
After installation, can try the simple example to see how to conduct analysis on hive.
set env
To use hadoop and hive conveniently, set the bin in Path. Just add the follow config into ~/.zshrc, and then source it source ~/.zshrc.
1 | export HADOOP_HOME=/usr/local/Cellar/hadoop/3.1.1/libexec |
running using beeline
beeline is a new hive client to replace the deprecated HiveCli. With beeline, you can execute write, load, query, etc. on hive.
To connect simply, type the following:
1 | $ hiveserver2 |
To create, alter database/table/column/etc. on hive, see Hive Data Definition Language.
To get the query commands, see LanguageManual Select
To load data from file, insert, delete, merge, update data, see DML (data manipulation language)
Other non-sql commands to use in HiveQL or beeline, see LanguageManual Commands. The Hive Resources related commands are non-sql commands.
Configure Hive
how to configure hive properties
To show hive config in hive cli: (show conf)
1 | # to show current: `set confName` |
There are two hive-site.xml files. See two hive-site.xml config files on HDP
/etc/hive/conf/hive-site.xml is the config for Hive service itself and is managed via Ambari through the Hive service config page.
/usr/hdp/current/spark-client/conf/hive-site.xml actually points to /etc/spark/conf/hive-site.xml . This is the minimal hive config that Spark needs to access Hive. This is managed via Ambari through the Spark service config page. Ambari correctly configures this hive site for Kerberos. Depending upon your version of HDP you may not have the correct support in Ambari for configuring Livy. The hive-site.xml in Spark doesn’t have the same template as Hive’s. Ambari will notice the hive-site.xml and overwrite it in the Spark directory whenever Spark is restarted.
analysis on hive
When you start a sql function (eg. select count(*) from xxx), it in fact starts an map-reduce job based on hadoop to search among all datanodes. Such functions are simple analysis implemented by hive.
Hive compiler generates map-reduce jobs for most queries. These jobs are then submitted to the Map-Reduce cluster indicated by the variable:
1 | mapred.job.tracker |
For complex analysis, you may need to write custom mappers (map data) & reducers (collect data) scripts. UseTRANSFORM keyword in hive to achieve this.
For example, the weekday_mapper.py to convert unixtime to weekday:
1 | import sys |
And then use the script:
1 | CREATE TABLE u_data_new ( |
storage on hive
Hive relies on Hadoop. The data in hive is saved in hdfs in fact. And the metadata is saved in mysql (the db can be configured). When check localhost:9870, you can see a new folder /user/hive/warehouse. All tables in hive are dirs in /user/hive/warehouse.
Hive Partition
hive中简单介绍分区表(partition table),含动态分区(dynamic partition)与静态分区(static partition)
Hive organizes tables into partitions. It is a way of dividing a table into related parts based on the values of partitioned columns such as date, city, and department. Using partition, it is easy to query a portion of the data.
Tables or partitions are sub-divided into buckets, to provide extra structure to the data that may be used for more efficient querying. Bucketing works based on the value of hash function of some column of a table.
For example, a table named Tab1 contains employee data such as id, name, dept, and yoj (i.e., year of joining). Suppose you need to retrieve the details of all employees who joined in 2012. A query searches the whole table for the required information. However, if you partition the employee data with the year and store it in a separate file, it reduces the query processing time. The following example shows how to partition a file and its data:
Hive bucket
hive partitioning vs bucket with examples
stack-overflow: hive partition vs bucket
1 | CREATE TABLE zipcodes( |
| PARTITIONING | BUCKETING |
|---|---|
| Directory is created on HDFS for each partition. | File is created on HDFS for each bucket. |
| You can have one or more Partition columns | You can have only one Bucketing column |
| You can’t manage the number of partitions to create | You can manage the number of buckets to create by specifying the count |
| NA | Bucketing can be created on a partitioned table |
| Uses PARTITIONED BY | Uses CLUSTERED BY |
partition 和 bucket 都是将大数据集拆成更小的数据集,加速查询处理的方式。比如按日期拆分区,很多分析只拿当天的分区,处理的数据量、读取的 hdfs 文件很少,就快。
最大的区别是 partition 拆数据就是按 column 值拆,bucket 拆数据是按 column hash 值拆,所以 bucket 最终的桶的数目是固定的,同时一个桶里可能有多个 column 值(parition 每个分区只会存一种 column 的值)
相对来讲,bucket 粒度可能更细。比如一个场景,我们将 order 按 date 分区,分区后每天的数据量还是特别大,如果我们很多查询/join是基于 employee,此时可以基于 employe_id 再分成更多的小集合,即按 employe_id 字段 hash 到 n 个桶里,这种拆桶方式特别有利于宏宇今天说的 map-side join,而且相比 partition,可以控制文件数量(有时想用的 partition 字段可能会分成特别特别多小分区,这个时候 bucket 就更合适些)
上边那个例子,假如 order 按 date+employee_id partition,分区就会特别多(对 hdfs namenode 造成大压力,hive metadata 也有压力),所以按 date partition, 按 employee_id bucket 就比较合适
ORC vs Parquet
ORCFile in HDP 2: Better Compression, Better Performance
Hive Transactional
Close:
1 | set hive.support.concurrency = false; |
architecture
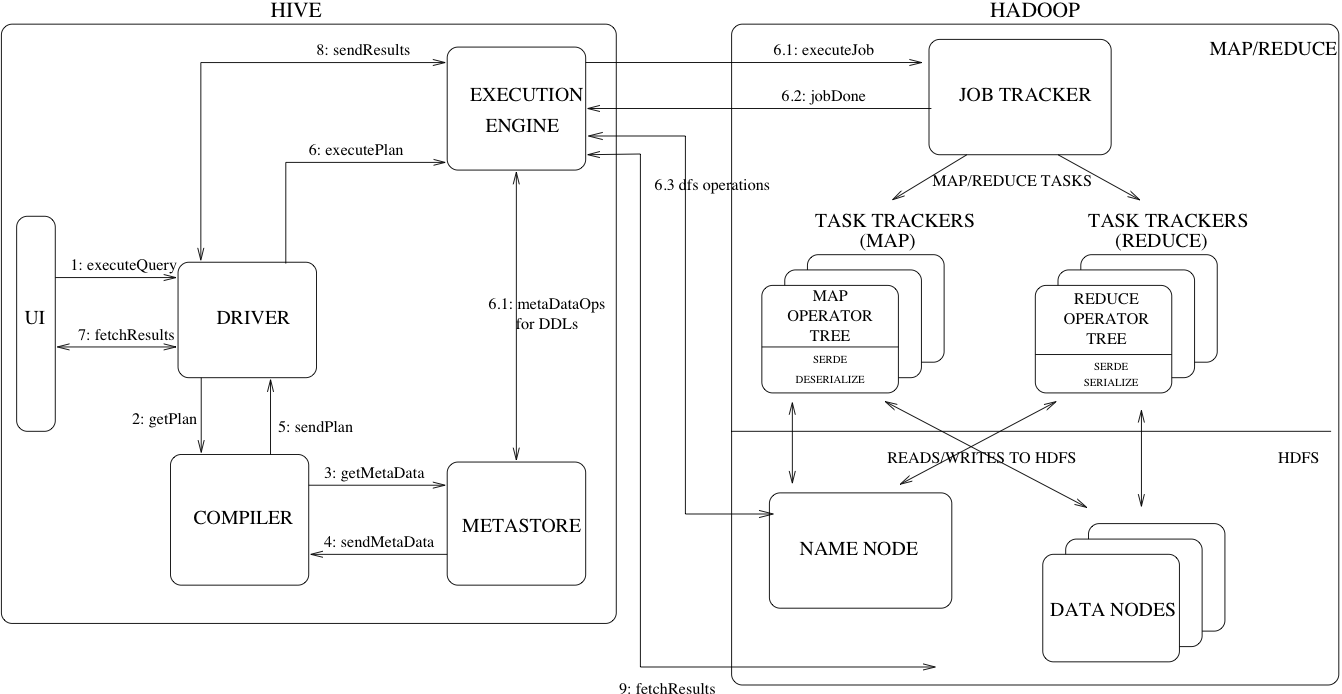
Hive Data Types
Common used commands
1 | 0: jdbc:hive2://slave1:2181> use dbname; |
auto increment id
two ways hive auto increment id
1 | ## use row_number |
get latest partition
1 | ## will only scan 2-3 partitions |
create table from another table
1 | CREATE TABLE new_test |
select all without some columns
1 | set hive.support.quoted.identifiers=none; |
select latest in group
use rank
1 | select * from ( |
hive cli pretty
1 | set hive.cli.print.header=true; // 打印列名 |
Optimization
小文件问题
和 spark 的小文件问题一样,hive 的运算引擎(mapreduce 或 Tez),为了提高性能,最后都会采用多个 reducer 来写数据,这个时候就会有小文件。不同于 Spark,Hive 本身提供了多种措施来优化小文件存储,我们只需要设置就行
1. 使用 concatenate
hive concatenate 主要针对 orc 和 rcfile 文件格式存储的文件,特别是 orc ,可以直接执行 stripe level 的 merge,省掉 deserialize 和 decode 的开销,很高效。(concatenate 可以执行多次,最终文件数量不会变化)
1 | ALTER TABLE table_name [PARTITION (partition_key = 'partition_value' [, ...])] CONCATENATE; |
2. 使用一些配置,在写文件时,自动 merge
输入时合并:
1 | -- 每个Map最大输入大小,决定合并后的文件数 |
输出时合并:
1 | -- hive 输出时合并的配置参数 |
Hive在对结果文件进行合并时会执行一个额外的map-only脚本,mapper的数量是文件总大小除以size.per.task参数所得的值,触发合并的条件是:
根据查询类型不同,相应的mapfiles/mapredfiles参数需要打开;
结果文件的平均大小需要大于avgsize参数的值。
Issues
count(*) return 0
1 | # 可以设,但不好 |
Its better not to disturb the properties on the statistics usage like hive.compute.query.using.stats. It impacts the way the statistics are used in your query for performance optimization and execution plans. It has tremendous influence on execution plans, the statistics stored depends on the file format as well. Therefore definitely not a solution to change any property with regards to statistics.
The real reason for count not working correctly is the statistics not updated in the hive due to which it returns 0. When a table is created first, the statistics is written with no data rows. Thereafter any data append/change happens hive requires to update this statistics in the metadata. Depending on the circumstances hive might not be updating this real time.
Therefore running the ANALYZE command recomputes this statistics to make this work correctly.
hive not recognizing alias names in select part
The where clause is evaluated before the select clause, which is why you can’t refer to select aliases in your where clause.
You can however refer to aliases from a derived table.
1 | select * from ( |
Side note: a more efficient way to write the last query would be
1 | select user, count(*) as cnt from rank_test group by user |
In, not in substitution
Hive supports sub-query in in , not in only after 0.13. And in may be slow, so we can replace it with join.
1 | -- in |
VERTEX_FAILURE
1 | set hive.exec.max.dynamic.partitions=8000; |
explain
1 | explain select sum(id) from my; |
\xa0
(SPACE_SEPARATOR, LINE_SEPARATOR, or PARAGRAPH_SEPARATOR) but is not also a non-breaking space ('\u00A0', '\u2007', '\u202F').
1 | print(res.selectExpr("trim(translate(mobile1, '\u00A0', ' '))").collect()) |